
Alucinaciones IA → 3 prompts + 1 sistema que hacen cualquier respuesta 100 % verificable
Por qué existen las alucinaciones y 6 técnicas profesionales para eliminarlas.

Hola, soy Alex dc. y todas las semanas te cuento cómo aprovechar la IA para mejorar tu negocio. Sin ruido. Solo consejos prácticos que generan resultados.
Antes que nada un saludo 👋 a los 788 nuevos miembros 👨🚀 desde la última publicación de La Mafia IA. Ya somos +13.000 y la newsletter #tech que más crece en español (según Substack) - Puedes suscribirte gratis aquí 👈
La IA no miente. Algo peor: improvisa.
Febrero de 2023. Google presenta su IA Bard al mundo.
En el primer vídeo de demostración oficial, Bard afirma que el telescopio James Webb tomó “las primeras imágenes de un planeta fuera de nuestro sistema solar.”
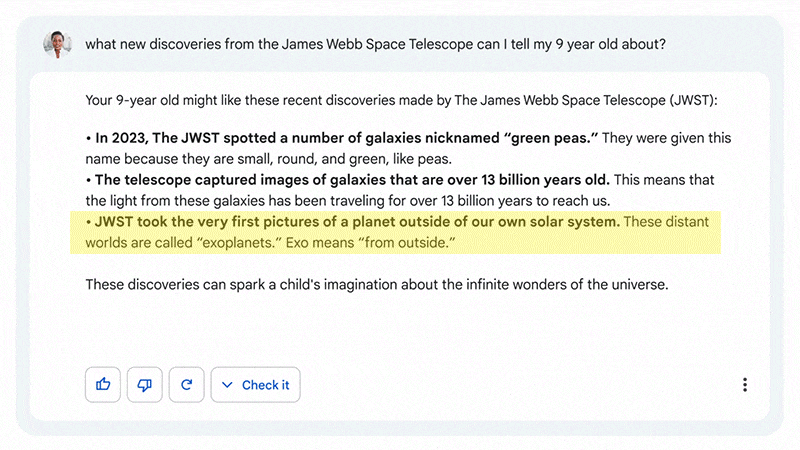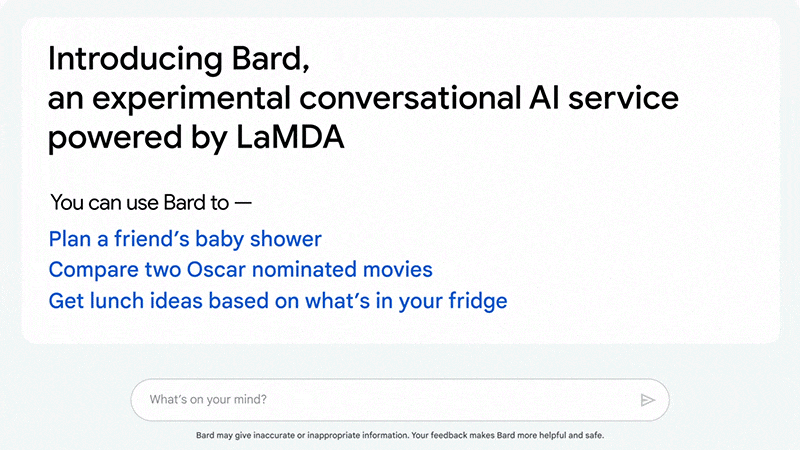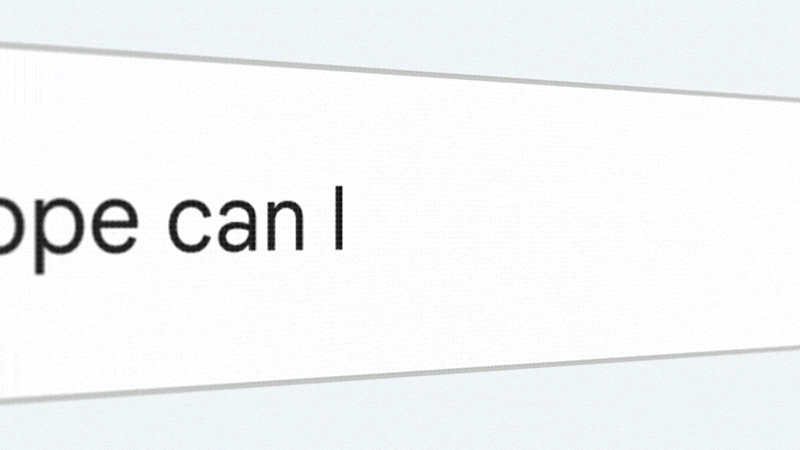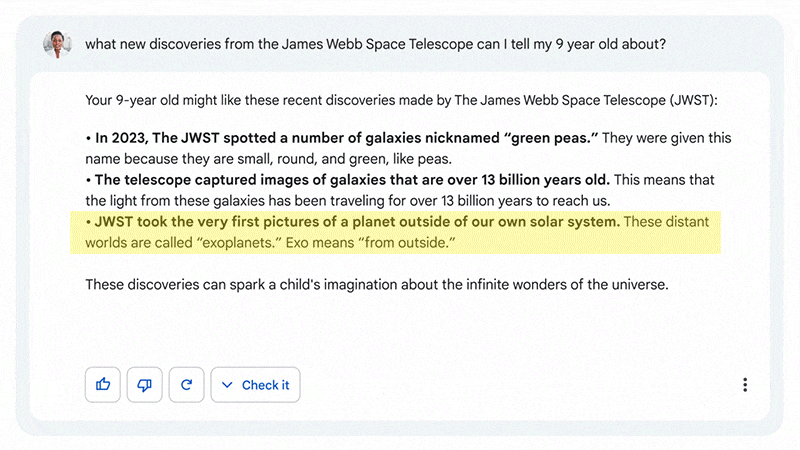
Era mentira.
El James Webb no fue el primero. Llevábamos décadas haciéndolo con otros telescopios (VLT, Hubble).
Un solo error. En el vídeo de lanzamiento. Delante de todo el mundo.
Al día siguiente, las acciones de Google cayeron un 9% 📉. Cien mil millones de dólares en capitalización bursátil. Evaporados en 24 horas por una alucinación.
Y lo más inquietante no es la cifra.
Es que nadie en Google lo detectó antes de publicar.
Eso es lo que hace que las alucinaciones sean peligrosas de verdad: no suenan a error. Suenan exactamente igual que una respuesta correcta. Con la misma confianza, la misma estructura, el mismo tono de autoridad.
Y eso da miedo.
El mismo miedo que tiene el consultor que no quiere firmar un informe con datos inventados. El abogado que no quiere presentar un caso con seis precedentes legales inventados por ChatGPT. El periodista. El analista financiero. El responsable de marketing que manda una propuesta con estadísticas fabricadas a su cliente más importante.
Es el miedo universal de cualquier profesional que trabaja con información generada con IA y se conoce como “alucinación”.
Quien sepa resolverlo de verdad dominará la IA.
Tanto para beneficiarse él mismo.
Como para vender la solución a otros y literalmente hacerse de oro.
Porque este problema lo tiene el despacho de abogados, la consultora, la agencia, la gestoría, el financiero. Todos. Sin excepción. Y todos estarían dispuesto a pagar generosamente.
El problema es que casi nadie entiende por qué ocurre. Y sin entender el origen, cualquier solución es un parche.
Así que esto es exactamente lo que vamos a ver hoy en La Mafia IA.
➡️ Lo que tienes a continuación no es otro listado de trucos de prompting. Es la explicación técnica de por qué la IA inventa, por qué lo hace con tanta convicción, y el sistema concreto que uso para evitarlo cuando los datos importan de verdad.
La IA no es un bibliotecario
La mayoría usa ChatGPT como si fuera un bibliotecario.
Le preguntas algo, va al archivo, te trae el dato exacto.
Pero la IA no es un bibliotecario.
Es un músico de jazz que, hace dos años, se leyó TODAS las partituras de todas las canciones del mundo.
Si le pides una canción, no va al archivo. Empieza a improvisar una melodía que suena similar a como sonaría ese canción si existiera. A veces acierta. A veces introduce pequeñas variaciones o mezcla canciones. Pero siempre suena bien.
La IA no es una base de datos que falla. Es un motor creativo que inventa.
El problema que es parte del diseño💡
Hay algo que casi nadie te explica sobre cómo funciona la IA por dentro. Y sin entenderlo, cualquier técnica de verificación que apliques será una tirita sobre una herida que no has diagnosticado.
Esta es la verdad que puede que te sorprenda:
Los LLMs siempre están alucinando.
No cuando fallan. Siempre.
Un modelo de lenguaje no tiene una base de datos de “hechos verdaderos” separada de su generador de texto.
No existe ese archivo al que acude cuando necesita ser preciso. Lo que existe es un sistema estadístico extraordinariamente sofisticado que predice qué palabra debería venir después de la anterior.
Cuando esa predicción coincide con el consenso que tenemos sobre la realidad, lo llamamos “acierto”.
Cuando la usamos para escribir un poema, hacer una imagen o crear algo desde cero, lo llamamos “creatividad”.
Cuando no coincide con lo que es verificable, lo llamamos “alucinación”.
No son tres comportamientos distintos. Es el mismo mecanismo con distintos resultados.
Y aquí está la paradoja que hace que este problema no tenga solución perfecta: si las empresas de IA lograran crear un modelo que jamás alucinara, tendrían que eliminar exactamente la capacidad que hace a la IA valiosa.
Para que una IA pueda inventar una solución nueva a tu problema de producto, necesita la misma maquinaria que la hace inventarse un fallo judicial de 1998.
La creatividad y las alucinaciones comparten motor.
Esto cambia radicalmente el enfoque del problema. Ya no se trata de cómo evitar que la IA alucine, sino de entender qué estamos buscando exactamente:
Cuando necesitamos aprovecharnos al máximo de su creatividad y potencial de pensamiento lateral, o
Cuando necesitamos aburrida precisión y absoluta veracidad.
Por qué ocurre esto (no es un fallo) 📍
Como ya sabemos, ChatGPT y el resto de LLMs han sido entrenados con cantidades masivas de texto con un único objetivo: predecir qué palabra viene después.
Eso es todo.
Optimizan para la probabilidad, no para la verdad. Y hacer que un texto suene bien muchas veces entra en conflicto directo con hacerlo preciso.
Hay dos razones concretas por las que los modelos están construidos para inventar con confianza:
Razón 1: Los modelos tienen más incentivos en responder, que en tener razón.
Cuando un LLM no sabe la respuesta a algo, tiene dos opciones: admitir incertidumbre o generar algo plausible.
La mayoría de los benchmarks sobre los que compiten las empresas de IA no dan puntos por decir “no sé”. Premian el intento.
Así que durante el entrenamiento, los modelos aprenden que lanzar una respuesta confiada es la estrategia ganadora.
Y como son extraordinariamente buenos con el lenguaje, sus respuestas inventadas suenan igual de autorizadas que las verdaderas.
Razón 2: Los datos de entrenamiento contienen toda la mierda de internet.
Los modelos aprenden de texto a escala masiva. Eso incluye lo mejor del conocimiento humano... y también nuestros errores, nuestros sesgos, nuestra información obsoleta y nuestras teorías conspirativas.
Cuando preguntas sobre algo poco documentado o reciente, el modelo rellena el hueco con lo que estadísticamente “suena bien”. No con lo que es cierto.
Pero aquí viene lo más sorprendente del asunto:
Los modelos saben cuando están mintiendo.
Al menos en gran parte.
Estudios sobre el comportamiento interno de LLMs han encontrado que los modelos retienen suficiente información interna para reconocer cuándo están pisando terreno inestable.
Simplemente no sacan esa incertidumbre a la superficie a menos que los fuerces a hacerlo.
Un experimento lo demostró de forma elegante: pidieron a un modelo que citara papers académicos, y luego le preguntaron repetidamente quiénes eran los autores de cada referencia. Para las referencias inventadas, el modelo daba respuestas inconsistentes en cada intento. Para los papers reales, acertaba consistentemente.
El modelo sabía la diferencia. Solo que no te lo iba a decir si no insistías.
👀 ¿Por qué importa esto? Porque, como veremos a continuación, obligar a la IA a explicitar su incertidumbre no es un truco de prompting. Es aprovechar información que el modelo ya tiene pero no comparte por defecto, para conseguir un resultado más útil.
La Ley de Brandolini 🔥
En 2013, el ingeniero Alberto Brandolini formuló lo siguiente:
“La cantidad de energía necesaria para refutar una tontería es un orden de magnitud mayor que la necesaria para producirla.”
Era verdad entonces. Ahora es una catástrofe.
Porque la IA ha hipercargado el lado de la creación hasta hacerlo prácticamente gratuito.
Esto se resume en lo siguiente:
↳ A una IA le cuesta 0,5 segundos inventarse tres fuentes de Stanford.
↳ A ti te cuesta 20 minutos abrir los PDFs, leerlos y confirmar que no estaban ahí. Si es que tienes acceso a los papers. Si es que sabes buscarlos.
El problema no es solo que la IA se equivoque. Es que ha convertido la verificación en un trabajo a tiempo completo.
⬅️ Antes de la IA generativa, desinformar requería esfuerzo humano. Alguien tenía que escribir el artículo falso, distribuirlo, darle credibilidad aparente.
➡️ Ahora cualquier usuario puede generar en segundos un informe de diez páginas con referencias que no existen, datos que suenan plausibles y una estructura que imita perfectamente la de un estudio real.
Los investigadores de la Universidad de Stanford documentaron en 2023 que el 28,6% de los textos generados por GPT-4 en tareas de escritura persuasiva contenían al menos un dato verificablemente falso. No errores de tono. Datos falsos. Con fuentes inventadas.
El coste de producir la mentira: un prompt.
El coste de detectarla: horas.
Eso ya no es un bug de la tecnología. Es un cambio estructural en cómo funciona la información.
3 Prompts para reducir las alucinaciones 💡 (técnicas básicas)
Antes de llegar al enfoque adversarial, que es donde está la solución real profesional, déjame darte las técnicas base. Son válidas. Tienen respaldo científico. Y los prompts están aquí para que los copies directamente y obtengas mejores resultados.
Prompt 1: Dale permiso explícito de decir “no sé”
Los modelos están entrenados para evitar la incertidumbre.
Tienes que anular eso de forma explícita.
Un estudio de Carnegie Mellon demostró que simplemente añadir permiso explícito para admitir incertidumbre, reduce significativamente las tasas de alucinaciones en tareas de búsqueda de hechos.
El prompt:
Si no estás seguro de algo, o si tu información podría estar
desactualizada, dímelo explícitamente. Prefiero que me digas
"no sé" a que me des información incorrecta que voy a actuar
como si fuera verdad.
Para cada afirmación que hagas, indícame tu nivel de confianza:
alto, medio o bajo.
[TU PREGUNTA O TAREA]Prompt 2: Chain-of-Thought - Obliga al razonamiento paso a paso
Un estudio publicado en EMNLP 2025 indica que el Chain-of-Thought (CoT) prompting reduce las alucinaciones en LLMs o que al menos mitiga su frecuencia. Es la intervención de prompting con más respaldo empírico que existe.
¿Por qué funciona? Porque cuando la IA debe mostrar cada paso de su razonamiento, las fabricaciones son más visibles. Si algo está mal en la cadena lógica, puedes ver exactamente dónde rompió.
El prompt:
Antes de darme una respuesta final, piensa paso a paso.
1. Identifica qué información es relevante para responder esto
2. Explica tu razonamiento para cada punto
3. Señala explícitamente cualquier área donde no estés seguro
o donde estés haciendo suposiciones
4. Solo entonces, da tu conclusión basada en los pasos 1-3
[TU PREGUNTA]Técnica 3: Instrucciones del sistema
Esta es la más potente de las técnicas estándar porque no la aplicas prompt a prompt. La configuras una vez y afecta a todas tus conversaciones.
En ChatGPT: Configuración → Instrucciones personalizadas → “¿Cómo te gustaría que respondiera ChatGPT?”
En Claude: Perfil → Instrucciones de Claude → campo de preferencias de respuesta.
En Gemini: Configuración → Extensiones → instrucciones personalizadas.
Lo que pegas:
No inventes datos, fechas, cifras, citas ni fuentes.
Si no estás seguro, indícalo explícitamente.
Si la información puede estar desactualizada, adviértelo.
Prefiero una respuesta incompleta y honesta a una completa e inventada.
Distingue claramente entre:
Hechos verificables
Suposiciones o estimaciones
Opiniones o interpretaciones
Es mejor ser transparente sobre límites que completar vacíos con conjeturas.Esto no soluciona el problema. Pero cambia el enfoque del modelo en cada conversación.
Si usas la IA profesionalmente para temas donde la veracidad de los datos sea clave (abogados, consultores, etc.) Es una configuración realmente obligatoria.
Nota: Ten también en cuenta que si eres alguien creativo, igual no vas a querer esta precisión en absolutamente todas tus interacciones con IA.
Relacionado👇

Pero esto no es suficiente…
¿Ves el patrón?
Técnica 1: Le pido a la misma IA que sea honesta sobre sus límites.
Técnica 2: Le pido a la misma IA que razone mejor.
Técnica 3: Le pido a la misma IA que priorice precisión sobre utilidad.
Todas dependen de que el mismo sistema que genera las alucinaciones también las detecte.
Es como pedirle al autor de un informe que haga el peer review de su propio trabajo. Hay un conflicto estructural de interés.
Puede intentarlo honestamente y aun así perderse los puntos ciegos más importantes.
El 18% de alucinaciones que quedan después del Chain-of-Thought (fuente) no es un error corregible con mejores instrucciones. Es el suelo de lo que puede hacer un sistema cuando se audita a sí mismo.
Para bajar de ese suelo, necesitas fricción externa.
Sistema Adversarial: Por qué necesitas un Red Team para que la IA deje de mentirte 🔴
Lo que voy a describir no es teoría. Es lo que hacen los equipos de seguridad en IA desde hace años, y lo que algunas personas empiezan a aplicar en su trabajo diario sin saber que tiene nombre.
Se llama Red Teaming.
En ciberseguridad, el Red Team es el equipo que ataca tu propio sistema para encontrar vulnerabilidades antes de que lo haga el enemigo.
Nadie confía en que el desarrollador encuentre sus propios bugs. Ponen a otro equipo a destrozarlo.
En IA, el mismo principio se llama LLM-as-a-Judge: usar un modelo de lenguaje para evaluar y atacar el output de otro.
Investigadores de Google DeepMind publicaron en 2024 evidencia de que los sistemas donde múltiples modelos debaten y se contradicen producen outputs significativamente más precisos que los sistemas donde un solo modelo se autocorrige.
La tensión entre diferentes IA genera resultados mejores que la reflexión solitaria.
La verdad rara vez surge de hacerle la pregunta perfecta a un solo oráculo. Surge del choque entre dos partes con intereses opuestos. Como en un juicio.
Crea tu sistema de seguridad: 3 prompts para auditar cualquier cosa
Estos no son “instrucciones para ser más cuidadoso”. Son el flujo de trabajo obligatorio para cualquiera que tenga la IA como herramienta fundamental en su trabajo.
Prompt 1: El Abogado del Diablo
Para cuando tienes un borrador, una estrategia, un argumento, o cualquier texto del que necesitas encontrar los puntos ciegos antes de que la realidad los encuentre.
Es uno de mis prompts favoritos. Lo uso en prácticamente todas mis conversaciones importantes con la IA.
Este sencillo prompt le hubiera ahorrado cien mil millones de dólares de pérdidas a Google el día del lanzamiento de su IA.
Prompt:
Actúa como el abogado de la parte contraria (o el crítico más
hostil de mi industria). Tu único objetivo es encontrar las
fallas lógicas, los sesgos y las debilidades en el argumento
que te presento.
No seas educado. Sé despiadado.
Enumera los 3 puntos donde mi caso/idea es más vulnerable a
ser destruido y dime exactamente qué evidencia necesitarías
para refutarme.
Aquí está el texto: [TU TEXTO]Prompt 2: El Auditor de Hechos con Datos Reales
Tomas el resultado de ChatGPT o Claude y lo llevas a una IA conectada a internet en tiempo real (mis dos preferidas son Perplexity y Grok).
A continuación te pego un texto generado por otra IA.
Actúa como un fact-checker profesional.
Tu trabajo no es evaluar el estilo. Es evaluar la verdad.
Busca en la web y audita cada afirmación fáctica, dato,
fecha o cita que aparezca en este texto. Devuélveme una
tabla con 3 columnas:
1. Afirmación
2. Veredicto (Verdadero / Falso / Inexacto / No verificable)
3. Fuente real encontrada o explicación del error
Si no encuentras una fuente primaria que avale una afirmación,
márcala como No verificable.
Texto a auditar: [PEGA AQUÍ EL TEXTO]Esto es hacer Red Teaming entre modelos. ChatGPT genera. Grok destruye. Tú decides.
Prompt 3: Fuentes exclusivas con tus Documentos
Para cualquier tarea donde trabajes con un PDF, contrato, informe o documento propio.
Previene las alucinaciones intrínsecas: las que ocurren cuando la IA “lee” tu documento pero rellena los huecos con invención.
Basándote SOLO en el documento adjunto, responde a mi pregunta.
Regla estricta: Antes de hacer cualquier afirmación, debes
extraer y citar textualmente la frase exacta del documento
que la respalda.
Si el documento no contiene la respuesta, di explícitamente:
"El documento no menciona esto."
No uses conocimientos externos.
Pregunta: [TU PREGUNTA]Sin cita textual, sin afirmación. Punto.
El gaslighting más sofisticado de la historia
Hay algo más sobre lo que nadie habla. Algo que es casi psicológico.
Cuando Excel se cuelga, sabes que Excel se ha colgado. No dudas de ti mismo.
Cuando la IA te miente, primero dudas de ti.
Porque la máquina es elocuente. Educada. Estructurada.
La IA no duda, no tartamudea, no dice “creo que”.
Entonces cuando se inventa esa fuente de Stanford y tú no la encuentras, el primer pensamiento no es “la IA se ha inventado esto”. El primer pensamiento es “debo haberla buscado mal”.
Lo sé porque me ha pasado. Muchas veces.
Eso no es un usuario siendo tonto. Es un humano lidiando con un ente lingüístico que imita a la perfección todos los marcadores que usamos para evaluar la fiabilidad de una fuente: confianza, estructura, coherencia, precisión aparente.
No estamos lidiando con un software con bugs, como cuando Excel se cuelga. Estamos lidiando con algo que imita los marcadores de la autoridad tan bien que nos hace dudar de nuestra propia cordura.
El framework para saber cuándo aplicar cada uno
No todo requiere el mismo nivel de verificación.
El exceso de paranoia también paraliza.
Riesgo bajo (brainstorming, ideas iniciales, borradores creativos): usa la IA con normalidad. Las alucinaciones pueden incluso abrir caminos inesperados. Las técnicas estándar son suficientes.
Riesgo medio (investigación para artículos, contenido que publicarás, decisiones menores): Técnicas 1-4, más el Prompt 1 (Abogado del Diablo). Spot-checks en afirmaciones clave.
Riesgo alto (información que usarás para tomar decisiones reales, contenido que citas en trabajo profesional, datos que afectan a terceros): los tres prompts adversariales más verificación manual de los datos críticos.
La regla es simple: el esfuerzo de verificación debe ser proporcional al coste de estar equivocado.
Un dato erróneo en tu newsletter es embarazoso. Un dato erróneo en un contrato o en un informe para un cliente tiene consecuencias reales.
Los abogados que citaron jurisprudencia inventada por ChatGPT en 2023 fueron sancionados por sus colegios. La IA no comparte el riesgo profesional. Solo tú.
Lo que te llevas de todo esto
Los modelos están mejorando. Cada nueva generación alucina menos que la anterior. La tendencia es clara.
Pero las alucinaciones no van a desaparecer del todo. Están integradas en cómo funcionan los modelos de lenguaje.
No son un bug que se corrige con suficientes actualizaciones. Son una consecuencia estructural de optimizar para la plausibilidad del texto.
Lo que sí va a cambiar es dónde está el trabajo.
Cada vez más en detectar errores sofisticados: los que suenan perfectamente razonables, que tienen la forma correcta de una respuesta verdadera, y que solo fallan en el detalle específico que importa.
Eso exige un nuevo conjunto de instintos:
Saber cuándo la IA está pisando terreno seguro: preguntas sobre conceptos bien documentados, síntesis de información que le has dado tú, razonamiento sobre contexto que controlas.
Saber cuándo está improvisando: datos específicos y recientes, citas exactas, detalles técnicos de nicho, cualquier cosa que requiera acceder a información que no está en su entrenamiento.
Y aquí está la verdad incómoda: verificar trabajo en áreas donde no eres experto es el problema más difícil de resolver.
Precisamente usas la IA porque no tienes esa expertise.
Entonces, ¿cómo detectas el error en el dominio donde más dependes de ella?
No hay respuesta perfecta. Pero sí hay prácticas:
☑ Configura unas instrucciones del sistema adecuadas a tu uso de la IA.
☑ Aplica el Sistema Adversarial cada vez que el coste de estar equivocado sea real.
☑ Usa herramientas con búsqueda web en tiempo real (Perplexity, Grok) para verificar datos factuales específicos. Comprueba las fuentes que citan. No asumas que porque cita una URL, esa URL contiene lo que dice.
☑ Desarrolla el hábito de preguntar “¿esto lo puedo verificar yo directamente?” antes de publicar, enviar o actuar.
La IA ha cambiado lo que significa ser competente con la información. Antes, el reto era encontrarla. Ahora, el reto es un buen juicio.
Y el juicio (saber qué creerte y qué no) es una habilidad humana que ningún modelo va a hacer por ti.
El objetivo no es desconfiar de la IA. Es usarla con los ojos abiertos.
Y los ojos abiertos empiezan por entender que lo que tienes delante no es un bibliotecario.
Es un músico de jazz extraordinario, que a veces le da por improvisar para lucirse.
Trátalo como tal.
Alex dc.
❤️ Gracias por leer La Mafia IA.
Si te ha gustado esta edición, házmelo saber, no te olvides de darle al ♡
¿Conoces a alguien a quien le pueda ayudar esta información? → compártelo.
🗞️ Para noticias IA diarias:
La Mafia IA no te bombardea con noticias (que solo añaden ruido y caos).
Si te interesa estar más al día: En mis perfiles en redes te comento las noticias más importantes en tiempo real, me puedes encontrar en:
𝕏 x.com | @Thread | 💼 Linkedin | 📒 Notas de Substack
Este post fue escrito por un humano. Las herramientas IA me ayudaron a investigar y organizar. El criterio, los ejemplos y las opiniones son 100% míos.
Buenos días. Es súper post. Gracias. Una pregunta, Google Notebook no reduce significativamente estás alucinaciones. No base su respuestas solo en las fuentes que le suministramos? De antemano gracias
Excelente tips. Gracias por compartir. Aunque ojo, Notebooklm o Afforai serían las que menos alucinan, cierto? Considerando que usan las fuentes que le damos...