


GPT-4.5 ❌ Claude 3.7 ❌ Grok 3 - ¿Quién Gana la última Guerra IA?
He probado durante 9 horas estas IA para que tu no tengas que hacerlo. Hay un claro ganador y una decepción.

La inteligencia artificial (IA) ha alcanzado un nuevo hito en 2025 con el lanzamiento de tres modelos de vanguardia: GPT-4.5 de OpenAI, Claude 3.7 Sonnet de Anthropic y Grok 3 de xAI.
Presentados en febrero, estos modelos no son meras actualizaciones; marcan un avance significativo en conversación, razonamiento y creatividad.
He empleado más de 9 horas en pruebas personales, análisis de datos técnicos y benchmarks, para que tú no tengas hacerlo y simplemente puedas usar el modelo más adecuado a tu uso real.
El objetivo final de esta newsletter es descubrir qué modelo es mejor en casos práctico. Fuera de esos benchmarks que estas compañías han puesto tan de moda y que parece que siempre favorece a quién publica el modelo. 😉
💡 Si solo te interesa que IA es mejor para tu uso particular puedes avanzar directamente a las conclusiones finales.
🧧Lanzamiento de LA MAFIA IA premium
Próximamente La Mafia IA tendrá una pequeña sección solo para suscriptores de pago.
¿Quieres 1 año Gratis? 👉 comparte con solo 4 amigos
Durante el próximo mes todos los que compartáis esta newsletter con tan solo 4 amigos tendréis un año de suscripción gratuita.
🚀 Ayuda a tus amigos a crecer con IA!
👉 Comparte con 4 amigos y ten un año gratis de acceso a La Mafia IA +
🎯 ¿Quieres patrocinar la próxima edición? Toda la info aquí.
Si todavía no estás suscrito, apúntate a esta newsletter IA totalmente gratis hoy, antes de que sea de pago y recibe en tu correo las actualizaciones más importantes de la IA 😎 ✊🏾
Las Leyes del Escalado IA
El impresionante avance de estos modelos se fundamenta en dos principios fundamentales conocidos como las "Leyes de Escalado", que determinan cómo aumentar la capacidad de la IA para responder preguntas difíciles.
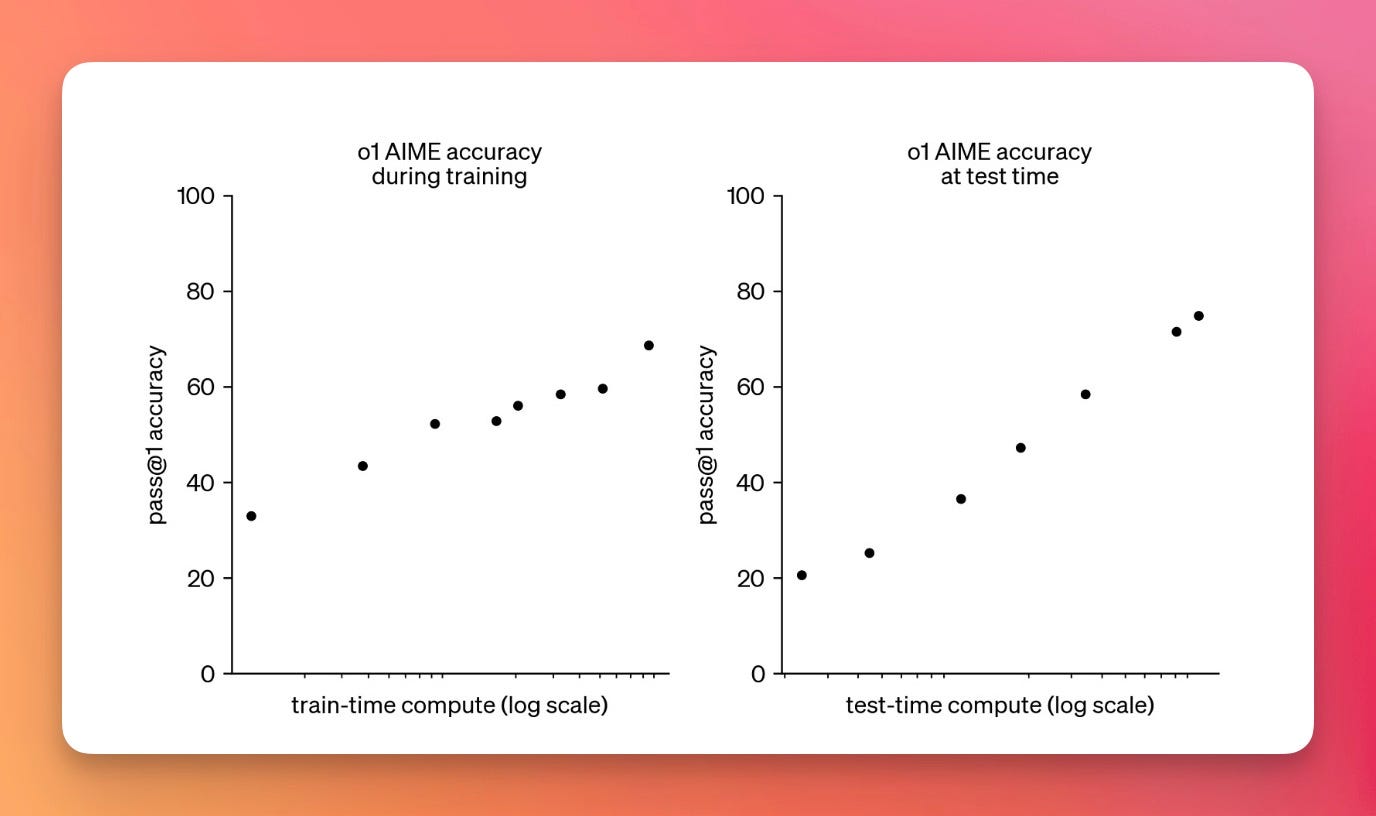
1️⃣ Primera Ley - Más computación
La primera ley, relacionada con el entrenamiento, establece que los modelos más grandes son inherentemente más capaces. Sin embargo, este crecimiento requiere un incremento exponencial en recursos: aproximadamente 10 veces más potencia computacional para obtener una mejora lineal en rendimiento.
Los modelos de tercera generación como Grok 3 utilizan más de 10^26 FLOPS (operaciones de punto flotante) durante su entrenamiento, una cifra casi inconcebible equivalente a ejecutar un smartphone moderno durante 634,000 años o la computadora de guía del Apolo durante 79 billones de años.
2️⃣ Segunda Ley - Más tiempo de inferencia
La segunda ley de escalado, igualmente crucial, revela que los modelos de IA mejoran significativamente cuando se les permite dedicar más tiempo computacional a resolver problemas individuales. Esta observación condujo al desarrollo de los "Reasoners" (Razonadores), modelos que aplican razonamiento paso a paso similar al humano.
Los nuevos modelos Gen3 incorporan esta capacidad de razonamiento cuando es necesario, combinando así las ventajas de ambas leyes: escala masiva en entrenamiento y capacidad de escalar al resolver problemas específicos.
El efecto combinado de estas leyes está impulsando una mejora acelerada en las capacidades de la IA mientras, paradójicamente, los costos disminuyen.
🤑 La Paradoja: Cuanto más potente las IA más baratas
Los modelos actuales ofrecen capacidades muy superiores a GPT-4 original por una fracción del costo: de aproximadamente $50 por millón de tokens que costaba GPT-4 inicialmente, hemos pasado a unos 12 centavos por millón de tokens con modelos incluso más capaces como Gemini 1.5 Flash.
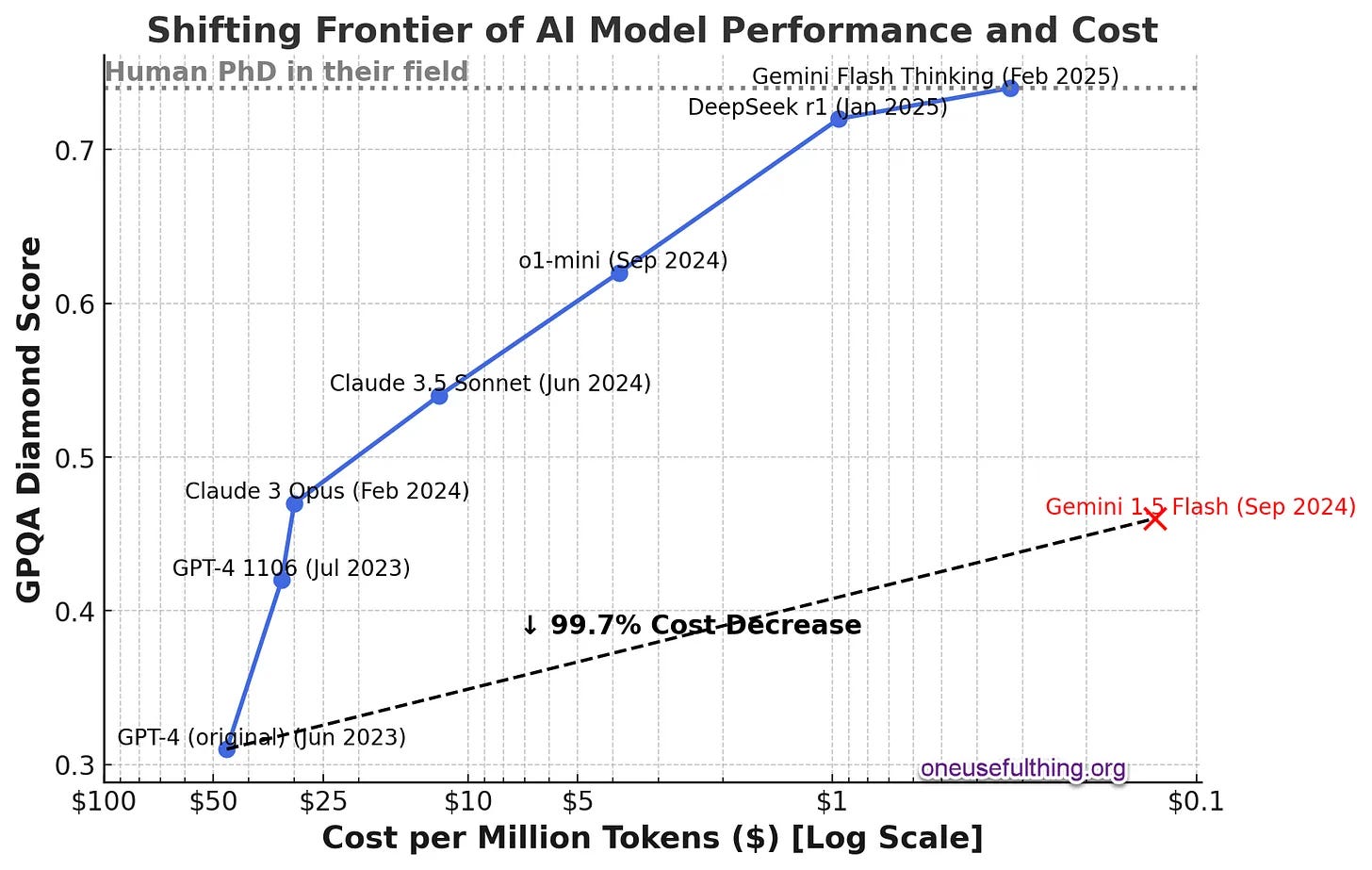
💥 Esta tendencia de mejora exponencial con reducción de costos plantea profundas implicaciones para empresas, emprendedores e individuos.
GPT-4.5 (OpenAI - ChatGPT)
Lanzado el 27 de febrero de 2025, GPT-4.5 es el modelo más grande y avanzado de OpenAI hasta ahora, con un enfoque claro en la inteligencia emocional por encima de la potencia bruta de razonamiento.
Sam Altman, CEO de OpenAI, lo describe como "el primer modelo que realmente siente como hablar con una persona reflexiva". (pero ya sabemos que al amigo Sam le gusta exagerar un poco…) 😅
Sin embargo, no está exento de críticas: Gary Marcus lo tilda de "lanzamiento vacío", y otros señalan que sus mejoras marginales no justifican su exagerado coste.
🎯 Características principales:
Rendimiento técnico: Precisión del 62.5% en SimpleQA (frente al 38.6% de GPT-4o) y reducción de alucinaciones al 37.1% (desde 59.8% en GPT-4o).
Inteligencia emocional: Detecta emociones y responde con empatía, evitando frases robóticas.
Costo y recursos: Requiere 10 veces más computación que GPT-4o, con un costo de $75 por millón de tokens de entrada y $150 por millón de salida (10-25 veces más caro que competidores como Claude). Entrenarlo costó aproximadamente $500 millones.
Accesibilidad: Disponible solo para usuarios de ChatGPT Pro por $200 al mes, lo que limita su adopción masiva.
🔥 Por qué es importante:
GPT-4.5 brilla en tareas que necesitan un toque humano, como redacción creativa o soporte al cliente. 👍
Sin embargo, su precio prohibitivo y consumo energético generan dudas sobre su viabilidad. 👎
Representa un punto de inflexión en la carrera de escalado de IA, sugiriendo que estamos alcanzando límites fundamentales.
Parece un modelo intermedio mientras buscan enfoques más sostenibles, con planes como el proyecto Stargate para 2025.
Claude 3.7 Sonnet (Anthropic)

Presentado el 24 de febrero de 2025, Claude 3.7 Sonnet es el modelo más inteligente de Anthropic hasta la fecha y el primero en ofrecer "razonamiento híbrido".
Combina respuestas rápidas con análisis profundos en un solo sistema, y su herramienta Claude Code lo convierte en un aliado clave para desarrolladores.
Anthropic lo ve como un paso hacia modelos que no solo asisten, sino que colaboran y eventualmente innovan por sí mismos.
🎯 Características principales:
Razonamiento híbrido: Modo de Pensamiento Extendido permite ver el proceso de razonamiento antes de la respuesta, con control sobre el contexto que añade profundidad (hasta 128K tokens).
Claude Code: Herramienta de línea de comandos que busca código, edita archivos, ejecuta pruebas y sube a GitHub. Empresas como Cursor lo consideran "el mejor para tareas de codificación reales".
Costo eficiente: $3 por millón de tokens de entrada y $15 por millón de salida, sin aumento de precio pese a las nuevas capacidades.
Benchmarks: Supera a competidores en SWE-bench Verified (problemas reales de software) y TAU-bench (tareas complejas con herramientas).
Creatividad: Genera visualizaciones 3D interactivas y pixel art con prompts mínimos. Esta nueva versión te puede ayudar a hacer "una semana de trabajo de nivel doctorado en segundos".
🔥 Por qué es importante:
Claude 3.7 redefine la IA para desarrolladores, ingenieros y creativos.
Vercel lo elogia por su "precisión excepcional en flujos de trabajo complejos", mientras que Canva valora su "código listo para producción con gusto por el diseño".
Su enfoque híbrido lo hace versátil y accesible, marcando una transición hacia modelos más autónomos.
Anthropic planea que para 2027, Claude "pioneree" soluciones que tomarían años a equipos humanos.
Respaldado por una valoración de $61.5 mil millones tras una ronda de financiación de $3.5 mil millones.
Grok 3 (xAI)
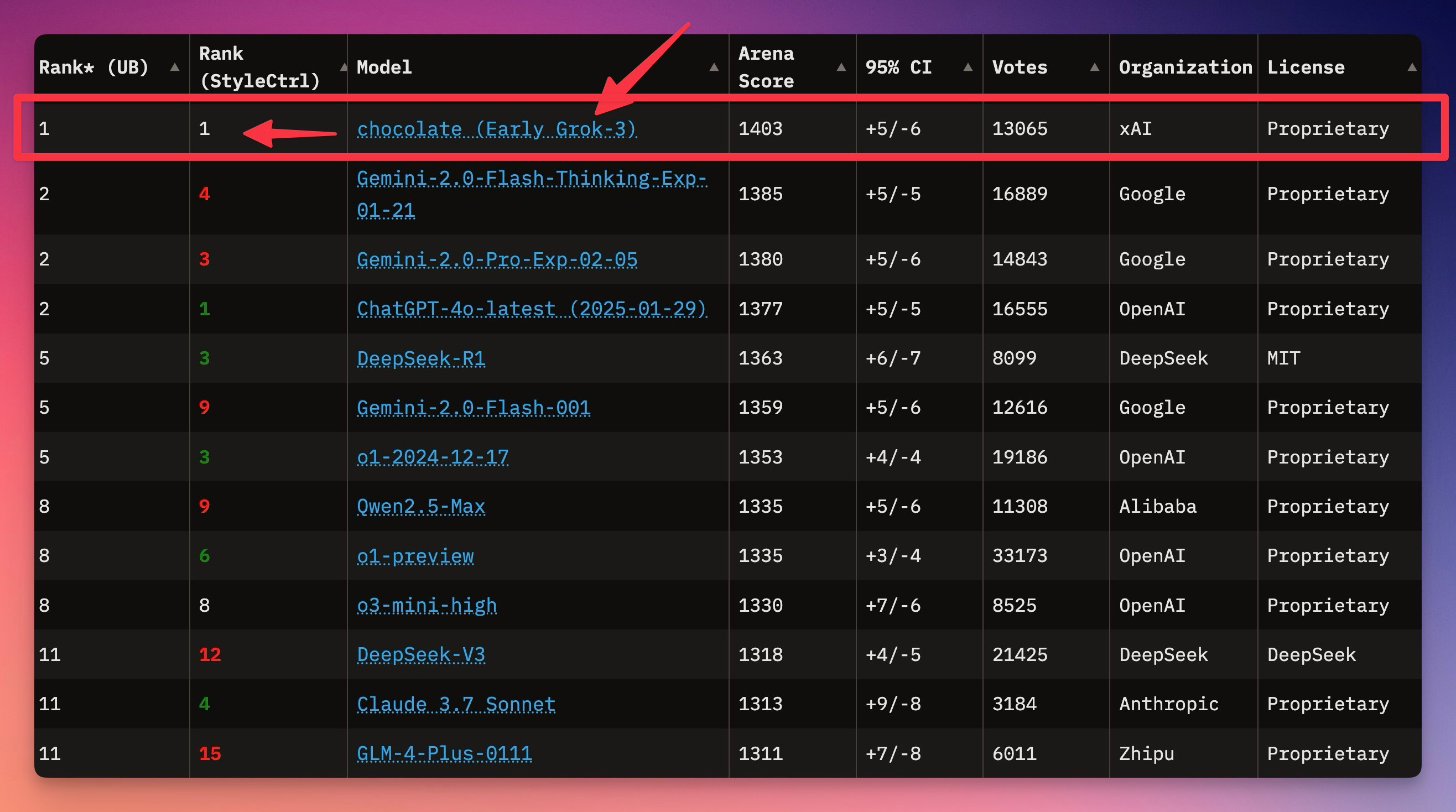
Lanzado el 17 de febrero de 2025, Grok 3 es el primer modelo Gen3 de xAI, anunciado por Elon Musk en un livestream.
Entrenado con 10^26 FLOPS en el supercomputador Colossus (100,000 GPUs H100), supera a modelos como Gemini-2 Pro, Claude 3.5 Sonnet y GPT-4o en benchmarks claves.
🎯 Características principales:
Poder computacional: 10^26 FLOPS, equivalente a correr un smartphone moderno por 634,000 años.
Modos de operación: Modo Pensar para razonamiento y Modo Cerebro Grande para problemas complejos. Incluye DeepSearch para investigaciones profundas.
Contexto masivo: 1 millón de tokens, 8 veces más que modelos anteriores.
Benchmarks: Líder en GPQA (ciencia de nivel graduado), MMLU-Pro (conocimiento general) y AIME (matemáticas competitivas). Usuarios lo rankean #1 en LLM Arena como "Early Grok-3".
Accesibilidad: Gratis para suscriptores Premium+ de X ($30/mes), con planes de API, modo de voz y eventual código abierto.
🔥 Por qué es importante:
Grok 3 es ideal para investigadores y creadores, con capacidades como generación de video desde texto y razonamiento avanzado. 👍
Su asociación con Musk genera escepticismo. Ya que se han detectado algunas instrucciones forzadas alineadas con Musk. 👎
Usuarios lo describen como "rápido, inteligente y divertido", aunque menos consistente en codificación Claude 3.7
Su adopción enfrenta retos por la desconfianza hacia Musk (el "coeficiente de rechazo"), pero su promesa de código abierto podría ser un diferenciador frente a competidores como DeepSeek, criticado por privacidad y seguridad. Andrej Karpathy lo equipara a o1 Pro ($200/mes), destacando su valor.
Implicaciones para el Futuro
Estos modelos traen oportunidades y desafíos:
Colaboración creativa: La IA ya no solo automatiza; genera ideas y soluciones innovadoras.
Sostenibilidad económica: Costos como los $500 millones de GPT-4.5 o el supercomputador Colossus de Grok 3 cuestionan su viabilidad a gran escala.
Adaptabilidad: Con avances rápidos, depender de un solo modelo es arriesgado.
Confianza y adopción: La percepción pública (e.g., rechazo a Musk o DeepSeek) influirá tanto como el rendimiento técnico.
Pruebas Prácticas y Conclusiones Finales
He empleado más de 9 horas en pruebas personales y análisis benchmarks, para que tu no tengas que perder este tiempo.
En este tiempo he evaluando áreas prácticas como programación, resolución de problemas, atención al cliente, automatización y precio, con el objetivo de determinar cuál es la mejor IA.
A continuación, te presento un análisis exhaustivo basado en datos técnicos, benchmarks y opiniones de expertos.
Buscando la mejor IA General
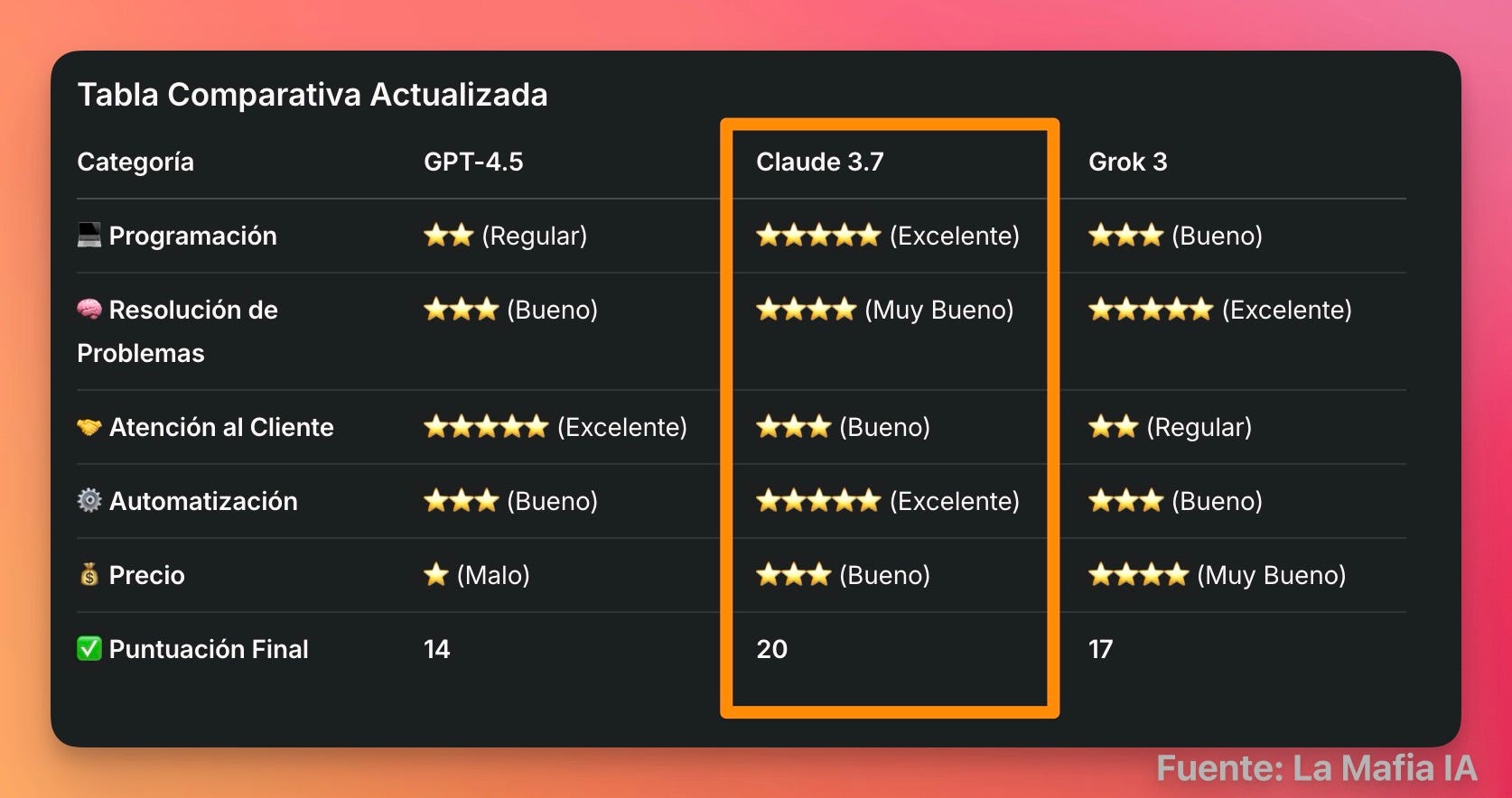
Los criterios de evaluación incluyen desempeño técnico, costo y accesibilidad, con una valoración cualitativa (Excelente ⭐️⭐️⭐️⭐️⭐️, Muy Bueno ⭐️⭐️⭐️⭐️, Bueno ⭐️⭐️⭐️, Regular ⭐️⭐️, Malo ⭐️) basada en la información disponible.
Programación/Codificación 💻
Claude 3.7: Líder en esta categoría, con un 70.3% en SWE-bench Verified y 62.3% en SWE Benchmark, superando a competidores como o3-mini (comparativa de codificación). Herramientas como Claude Code permiten buscar código, editar archivos y ejecutar pruebas, lo que lo hace ideal para desarrolladores.
Grok 3: Competitivo, con un 80.4 en LiveCodeBench (v5) para su versión mini beta, pero menos consistente que Claude 3.7 en tareas reales, según análisis de xAI.
GPT-4.5: No se destaca en codificación, mi conclusión tras algunas horas de pruebas es que es "perezoso en proyectos complejos". Su precisión en tareas de codificación es limitada, con un enfoque más en inteligencia emocional.
Resolución de Problemas 🧠
Claude 3.7: Muy bueno, con un 96% en ciertos datasets matemáticos y 80% en MMLU, gracias a su razonamiento híbrido, que permite alternar entre respuestas rápidas y profundas.
Grok 3: Excelente, con 92.7% en MMLU y ~89% en GSM8K para matemáticas, respaldado por su arquitectura de 2.7 trillones de parámetros y modos como "Big Brain" para problemas complejos.
GPT-4.5: Buen rendimiento en conocimiento general, con 89-90% en MMLU, pero inferior en matemáticas avanzadas y razonamiento lógico, con un 62.5% en SimpleQA.
Atención al Cliente 🤝
GPT-4.5: Excelente, diseñado para inteligencia emocional, con respuestas empáticas y naturales, evitando frases robóticas. Sam Altman lo describe como "hablar con una persona reflexiva".
Claude 3.7: Bueno, versátil para interacciones, pero menos enfocado en empatía, con un enfoque más técnico. Puede manejar consultas, pero no es su fuerte principal.
Grok 3: Regular, más orientado a razonamiento avanzado que a interacciones humanas, con reseñas que lo describen como "amigable" pero no óptimo para soporte al cliente
/ref: comparativa de chatbots
Automatización ⚙️
Claude 3.7: Excelente, con Claude Code que automatiza flujos de trabajo de codificación, como buscar código, editar archivos y ejecutar pruebas, ideal para desarrollo de software (detalles).
Grok 3: Regular, con capacidades avanzadas, pero sin herramientas específicas para automatización mencionadas, y su enfoque está más en razonamiento que en flujos repetitivos.
GPT-4.5: Bueno para tareas generales, pero su alto costo ($75/$150 por millón de tokens) lo hace menos práctico para automatización a gran escala. Puede integrarse vía API, pero carece de herramientas específicas.
Precio 💰
GPT-4.5: Alto, con $75 por millón de tokens de entrada y $150 por salida, o $200/mes para ChatGPT Pro, lo que lo hace prohibitivo para uso intensivo.
Claude 3.7: Medio, con $3 por millón de tokens de entrada y $15 de salida, competitivo para usuarios moderados, especialmente en tareas técnicas (Comparativa precios ).
Grok 3: Bajo para usuarios intensivos, con acceso ilimitado por $40/mes en X Premium+, pero requiere suscripción, y se espera un API empresarial con precios por uso (detalles de precios).
Conclusiones Finales: Cuál es mejor?
Los modelos presentados en los últimos días son el presente y futuro de la IA: modelos que conversan, razonan y crean como nunca antes.
Sin embargo podemos ver un claro ganador y perdedor:
🏆 Claude 3.7 es un claro vencedor! combina versatilidad y accesibilidad para desarrolladores, ofrece los mejores resultados en algo tan complejo (y útil para cualquier emprendedor), como es la programación.
👉 Grok 3 ofrece potencia bruta que da muy buenos resultados generales, a un coste optimizado. Su opción “DeepSearch” es una extraordinaria herramienta con unos resultados comparables a los de OpenAI pero a una fracción de precio. En mi uso personal es la que mejor respuestas me ha dado a la hora de resolver problemas.
❌ GPT-4.5 es a mi juicio el claro perdedor. Apuesta por la empatía a un costo elevado; salvo que estes usando la IA para automatizaciones de atención al cliente, no creo que el coste justifique su uso.
👀 Links de las Herramientas:
Modelos LLM Alternativos
DeepSeek - Modelo Chino con buenos resultados y especialmente un API con la mejor relación calidad/precio en la mayoría de las tareas.
Qwen - El modelo del gigante Alibaba, que presume de estar en la cabeza de los rankings de LLM, es GRATIS y además también te genera imágenes y videos IA.
Perplexity - Mi herramienta IA favorita (aunque con los avances de los que te hablo justo en esta newsletter esta perdiendo algo)
❤️ Gracias por leer AI Mafia.
Si te ha gustado esta edición, no te olvides de dar al ♡ y de compartirla por redes sociales o por email con otras personas a las que creas que les pueda gustar.
También nos gustaría escuchar tus opiniones y sugerencias, así que no dudes en responder a este correo. O dejar un comentario abajo.
Si quieres mantenerte al día en IA:
📺 Youtube: IA para emprendedores en Youtube
📢 Comunidad en Telegram: https://t.me/AImafiaClub. (Ya somos +1,4k 💪🏾)
🐦 X: @aimafiaclub
PD: Este correo electrónico fue escrito totalmente por un humano. En concreto por mi ☝️ @alex_dc 😉
Nos vemos en la próxima edición de La Mafia IA…
🎯 Ya somos una comunidad de más de 25.000 👉 ¿Quieres patrocinar la próxima edición? Toda la info aquí.
Me ha parecido especialmente interesante tu explicación sobre las Leyes del Escalado. La comparación con el smartphone funcionando durante 634,000 años es brutal y ayuda a visualizar la magnitud de estos modelos. Es impresionante cómo el aumento de tiempo de inferencia puede mejorar la calidad de las respuestas.
Team Anthropic 🙌