
🟡 IA Local: Gratis, privada y potente
300€ vs 0€ - La IA que no debería existir: gratuita, privada y sin limites que puedes ejecutar en tu ordenador.
Hace un año, si querías IA de nivel GPT-4, tenías que pagar a OpenAI.
Luego a los laboratorios se les ocurrió que 20€ no era suficiente y multiplicaron x10.
Y de los creadores de las suscripciones de 200€, presentamos los 300€ por usar la última versión de Grok 4.
No me entiendas mal. Creo que lo valen.
Si hace 3 años nos dicen que por 500€ íbamos a tener la mitad, habría que estar loco para no tirárselos a la cara.

Pero el mundo ha cambiado.
Ya no es lo que era hace 3 años.
Ya no podemos pensar como lo hacíamos hace 3 años.
Hoy, puedes descargar modelos en tu portátil que superan a lo que teníamos ahí.
Y desde luego, si me dan a elegir dos productos similares pero con 300€ de diferencia, no sé tú pero yo lo tengo bastante claro.
Pero hay algo más profundo que un simple “ahorro”. Hay un cambio de paradigma completo que pocos están viendo.
Y es el tema central de este artículo.
Pero antes que nada un saludo 👋 a los 348 nuevos miembros 👨🚀 desde la última publicación de La Mafia IA. Ya somos +15.000 y la newsletter #tech que más crece en español (según Substack) - Puedes suscribirte gratis aquí 👈
Soy Alex dc. y todas las semanas te cuento cómo aprovechar la IA para mejorar tu negocio. Sin ruido. Solo consejos prácticos que generan resultados.
✱ Recuerda que hay artículos que solo los recibirás si eres miembro ✱
🔎 La IA que no debería existir: Modelos Open Source
Mientras las Big Tech siguen subiendo precios y limitando el acceso a sus modelos más potentes, algo está pasando en silencio.
Los modelos open source ya no “compiten” con ChatGPT o Claude.
En algunos aspectos: Los superan.
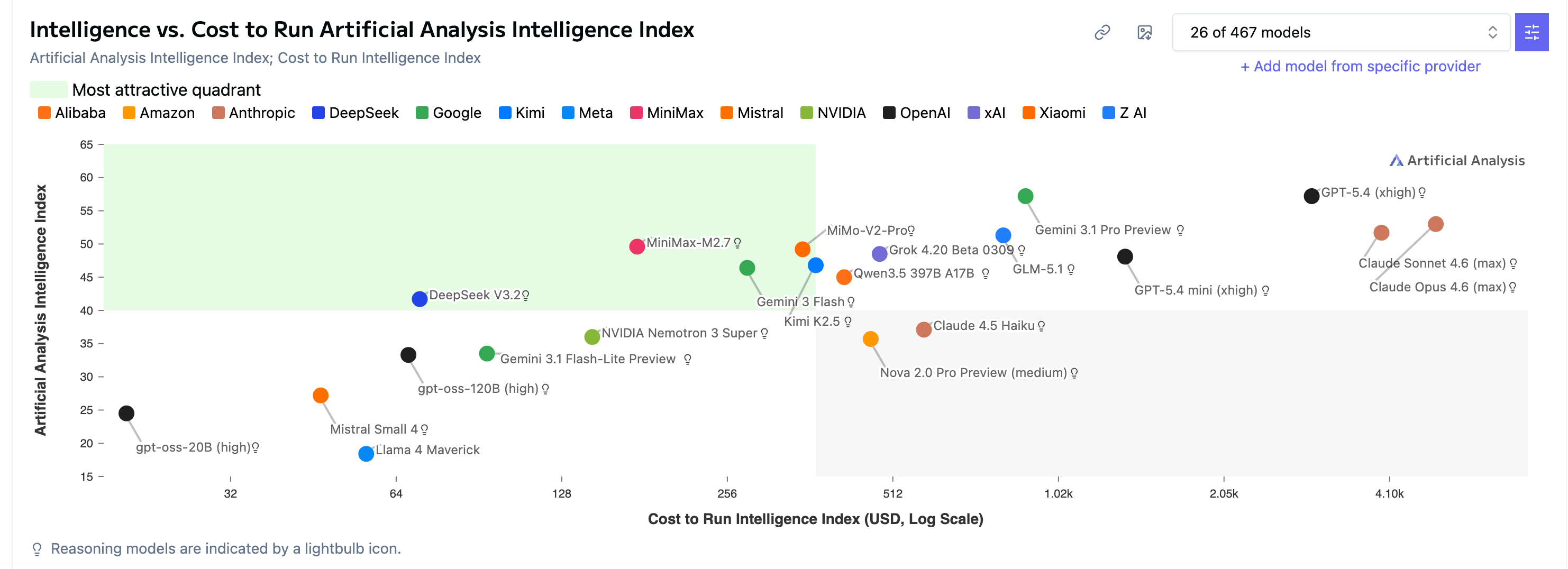
Y los últimos (Gemma 4 de Google, Qwen 3.6 de Alibaba, GLM 5.1, Kimi K2.6 de Moonshot) están al nivel SOTA con Claude Opus 4.6, Gemini 3 Pro y GPT-5.4. Hablamos de modelos frontier. Los gordos.
Puedes ejecutarlos en tu ordenador (aunque algunos requieren servidores más potentes). Sin internet. Sin compartir datos. Con toda la privacidad y… “gratis”.
¿No te parece una locura?
Pero lo más loco es que la mayoría estamos ignorando estos modelos o ni siquiera conocemos su potencial.
Asociamos Open Source a algo amateur.
Seguramente porque la comunidad que desarrolla estas herramientas nunca se ha preocupado mucho del marketing.
Pero la realidad es que conocer estos modelos no solo optimiza el coste, sino que en muchas aplicaciones resulta más útil que la API de Claude/Chatgpt.
Y además no te están drenando tu cuenta bancaria como si te hubieras dejado el grifo abierto antes de irte de vacaciones.
Y por eso, amigos, es por lo que existe La Mafia IA ;)
💎 El Fin del “Más Grande = Mejor”
Aquí está la verdad que nadie te cuenta:
La industria comunidad está dejando atrás la idea de que “más grande siempre es mejor” para entrar en una era de eficiencia, donde los modelos pequeños y el ecosistema abierto son los protagonistas.
NVIDIA y Georgia Tech publicaron un paper llamado “Small Language Models are the Future of Agentic AI” que plantea algo que debería cambiar cómo piensas sobre IA:
Usar un modelo masivo para cada pequeña tarea de un flujo de trabajo automatizado es costoso, lento e ineficiente. Es como contratar a un cirujano para ponerte una tirita.
La solución que proponen: sistemas heterogéneos. Modelos pequeños especializados para tareas rutinarias. Los modelos grandes solo entran cuando hay razonamiento profundo de verdad.
Y aunque en la era de la IA es difícil adivinar cuál va a ser la mejor estrategia dentro de una semana, parece que:
Un equipo de agentes pequeños, de código abierto y especializados es mucho más ágil y económico que un solo modelo masivo intentando hacerlo todo.
Y la tecnología acaba de ponérselo en bandeja a cualquiera.
🔥 Gemma 4: Google Suelta una Bomba Open Source
El 2 de abril de 2026, Google DeepMind lanzó Gemma 4.
Un modelo de 31.000 millones de parámetros que se coloca como número 3 entre TODOS los modelos abiertos del mundo en el leaderboard de Arena AI. Compitiendo directamente contra modelos que tienen 20 veces más parámetros.
Esto significa que Gemma 4 puede ejecutarse en ordenadores de consumo. Yo mismo lo tengo instalado en mi portátil ahora mismo.
Pero lo interesante no es solo el ranking. Lo interesante es lo que hay detrás.
Los datos que importan:
AIME 2026 (matemáticas): 89.2% el 31B y 88.3% el 26B. Para contexto: Gemma 3 de 27B se quedaba en un patético 20.8%. El salto generacional es brutal.
LiveCodeBench v6 (coding): 80% y 77.1% respectivamente
GPQA Diamond (ciencia avanzada): 84.3% y 82.3%
Arena AI Elo: 1452 (el 31B), muy cerca de GLM5 con 1456 y Qwen 3.5 con 1450
Y el 26B ni siquiera es denso. Es un Mixture of Experts con 25.200M de parámetros totales pero que solo activa 3.800M durante la inferencia (la cantidad de cerebro que “enciende” por consulta).
Resultado: en mi portátil* se ejecuta a unos 80 tokens/segundo. Lo que viene a ser una velocidad equivalente a la que te da ChatGPT incluso superior.
Rendimiento de modelo grande con el coste computacional de uno mucho más pequeño.
*si alguien se lo pregunta tengo un Macbook M4 max
Por qué Gemma 4 es diferente:
1. Licencia Apache 2.0. Cambio enorme respecto a versiones anteriores. Puedes usar estos modelos en proyectos comerciales, redistribuirlos, modificarlos. Sin cláusulas restrictivas, sin letras pequeñas. Si estás montando un producto con IA, esto importa mucho más de lo que parece.
2. Pensado para agentes desde el diseño. Function calling nativo, salida JSON estructurada, system prompts configurables. No es un chatbot al que le pones herramientas encima. Es un modelo construido para que tus agentes interactúen con APIs y herramientas externas de forma nativa.
3. Multimodalidad real. Toda la familia procesa imágenes. Los modelos pequeños (E2B y E4B) además procesan audio. OCR, comprensión de documentos, análisis de interfaces, transcripción de voz… todo corriendo localmente.
4. Del móvil al servidor. Cuatro tamaños: E2B y E4B para dispositivos (móviles, Raspberry Pi), 26B MoE para portátiles con buena GPU, y 31B denso para hardware serio. Ventana de contexto de hasta 256K tokens.
Google hasta ha colaborado con Qualcomm, MediaTek y NVIDIA para optimizar el despliegue en distintos dispositivos. Cuando una big tech se pone las pilas con el ecosistema, las cosas se mueven rápido.
Lo que NO hace:
Seamos honestos. Gemma 4 no genera imágenes ni vídeo, procesa entrada multimodal, pero la salida siempre es texto. Audio solo funciona en los modelos pequeños. Y la comunidad ya reporta que la calidad varía según cómo configures el prompt y qué engine uses.
Google recomienda temperature 1.0, top P 0.95 y top K 64 como punto de partida. Vas a necesitar experimentar.
Y el 31B en BF16 necesita unos 59GB de VRAM. En cuantización Q4 baja a ~17GB, pero la calidad se compromete parcialmente.
Aun con eso: la relación rendimiento-por-parámetro es la mejor que ha publicado Google. Punto.
⚡ Los Gigantes Chinos: Qwen 3.6 y Kimi K2.5
Si Gemma 4 es la bomba de Google, China lleva meses bombardeando sin parar.
Qwen 3.6: El Ecosistema Completo
Alibaba lanzó la familia Qwen 3.6 justo cuando estaba revisando el artículo para su envío 👋. Estas son algunas de las características de Qwen:
Flagship 397B-A17B: 397.000M de parámetros totales, pero solo activa 17.000M por consulta. Arquitectura MoE con eficiencia absurda.
AIME 2026: 91.3% — por encima de Gemma 4.
IFBench (seguimiento de instrucciones): 76.5%, superando a GPT-5.2 (75.4%) y aplastando a Claude (58.0%).
201 idiomas. 256K tokens de contexto nativo, extensible hasta 1M tokens en la versión Plus.
Pero lo que me parece más espectacular es lo que pasa en los modelos pequeños:
A falta de resultados del recién lanzado (hace horas) Qwen 3.6, Qwen3.5-9B supera al GPT-OSS-120B de OpenAI (un modelo 13 veces más grande) en GPQA Diamond, HMMT y MMMU-Pro.
Lee eso otra vez. Un modelo de 9.000 millones de parámetros superando a uno de 120.000 millones.
Esto es eficiencia real. Esto es lo que el paper de NVIDIA predijo: modelos pequeños, especializados, ganando a los mastodontes.
Y por si fuera poco, en marzo Alibaba soltó Qwen 3.6 Plus Preview con 1 millón de tokens de contexto. Gratis en OpenRouter. Con chain-of-thought siempre activo. 3x más rápido que Claude Opus 4.6 según tests de la comunidad.
Kimi K2.5: El Agente Autónomo
Moonshot AI (respaldado por Alibaba y HongShan) lanzó Kimi K2.5 en enero 2026 y trajo algo que ningún otro modelo open source tenía:
Agent Swarm. Puede coordinar hasta 100 sub-agentes trabajando en paralelo, manejando flujos de hasta 1.500 pasos coordinados. No es un modelo que chatea. Es un modelo que actúa.
1 trillón de parámetros totales, 32B activos por inferencia
Kimi K2 Thinking puede ejecutar 200-300 llamadas a herramientas secuenciales sin intervención humana
BrowseComp: 60.2% con Agent Swarm vs 29.2% de la línea base humana
Visual coding: convierte prompts conversacionales en código de interfaz completo con interacciones y animaciones
Licencia MIT Modificada
Y ya existe Kimi Code, su herramienta CLI que compite directamente con Claude Code. Funciona con VSCode, Cursor y Zed.
El hecho de que puedas tener un sistema de agentes paralelos, open source, ejecutando tareas complejas de forma autónoma... esto era ciencia ficción hace 18 meses.
🧠 TurboQuant: El Avance Invisible que lo Cambia Todo
Ahora bien, tener modelos brutales no sirve de nada si no puedes ejecutarlos. Y aquí es donde entra el avance que menos titulares genera pero que más impacto tiene.
Google Research publicó TurboQuant el 24 de marzo de 2026. Es un algoritmo de compresión que reduce el caché KV, la “memoria de trabajo” del modelo durante la inferencia, a solo 3 bits.
¿Y qué significa esto en cristiano?
Imagina que tu modelo es un estudiante en un examen. El caché KV es su memoria a corto plazo: todo lo que ha leído y necesita recordar para responder. Cuanto más largo el texto de entrada, más memoria necesita. Y esa memoria consume VRAM de tu GPU como una esponja.
TurboQuant comprime esa memoria 6x sin perder precisión. Y acelera los cálculos de atención 8x en GPUs NVIDIA H100.
Sin reentrenamiento. Sin fine-tuning. Con precisión idéntica al modelo original.
En el benchmark “Needle-in-a-Haystack” (encontrar una frase específica entre 100.000 palabras), TurboQuant mantuvo el 100% de precisión en cada nivel de cuantización probado. La comunidad lo ha replicado con Llama-3.1-8B y Mistral y confirman los resultados.
¿Por qué esto importa para ti?
Porque significa que modelos que antes necesitaban hardware de servidor ahora caben en tu portátil con GPU decente. Y que las ventanas de contexto largas (100K+ tokens) — que antes eran un lujo de las APIs de pago — ahora son viables en local.
Un usuario en la comunidad lo resumió perfecto: modelos corriendo localmente en un Mac Mini acaban de mejorar drásticamente, permitiendo conversaciones de 100.000 tokens sin la degradación de calidad habitual.
TurboQuant, combinado con la cuantización de pesos (GPTQ, AWQ, GGUF), hace que ejecutar modelos grandes en hardware de consumo sea algo que ya está pasando.

📊 El Nuevo Mapa: Quién Reemplaza a Quién
Los modelos closed-source tienen su equivalente open source:

La ventaja injusta: mientras tus competidores pagan APIs, tú tienes control total y costes ajustado o casi cero.
🏗️ De Cero a IA Local: Tu Guía de Arranque
Vamos a lo práctico. Tienes un ordenador. Quieres probar esto. ¿Cómo empiezas?
Paso 0: ¿Qué tienes?
Antes de nada, mira cuánta RAM tiene tu equipo:
8GB RAM → Puedes ejecutar modelos de 2-4B parámetros. No es un Ferrari, pero funciona. Piensa en un asistente para emails, resúmenes y preguntas rápidas.
16GB RAM → Tu sweet spot. Modelos de 7-9B que compiten con GPT-4o. Aquí ya empiezas a ahorrar dinero de verdad.
32GB RAM → Territorio serio. Modelos MoE como Gemma 4 26B o Qwen3.5-35B-A3B. Rendimiento de modelo frontier.
+32GB RAM con GPU dedicada → Gemma 4 31B, Kimi K2.5 cuantizado.
No te preocupes si estás en la franja baja. La interesante del ecosistema actual es que hay modelos que ya dan muy buenos resultados para cada nivel de hardware.
¿El hardware no te da? Los modelos funcionan con menos memoria usando disk offloading. Van más lentos (1-2 tokens/segundo vs 5-10), pero funcionan.
Paso 1: Instala tu primera herramienta
Si nunca has ejecutado un modelo local, empieza por LM Studio. Sin discusión. Funciona en Windows, Mac y Linux.
Ve a lmstudio.ai y descarga el instalador para tu sistema.
Ábrelo. Te pregunta tu nivel de experiencia → selecciona lo que quieras, no afecta a nada importante.
En la pestaña “Discover”, busca “Gemma 4” o “Qwen 3.5”.
Elige una versión Q4_K_XL (el balance perfecto entre calidad y velocidad).
Espera a que descargue (unos minutos dependiendo de tu conexión).
Haz click en “Chat”. Ya está. Estás usando IA Abierta en tu ordenador, sin internet, sin pagar nada.
🔥 Bonus: Configura los parámetros según el modelo:
Para Gemma 4:
Temperature: 1.0
Top P: 0.95
Top K: 64Para Qwen 3.5:
Min P Sampling: 0
Repeat Penalty: Deshabilitado
Temperature: 0.6
Top K: 20
Top P: 0.95Eso es todo. 10 minutos. Si has llegado hasta aquí y ya lo has hecho, enhorabuena: tienes más ventaja que el 95% de profesionales que siguen pagando suscripciones.
🛠️ 10 Herramientas esenciales para empezar con IA en local.
Puedes empezar SOLO con LM Studio (5 minutos) e ir añadiendo herramientas según las necesites. No hace falta montarlo todo de golpe.
🥇 Nivel 1: Para empezar HOY
➤ LM Studio 🔗 lmstudio.ai
🖥️ (Windows · macOS · Linux)
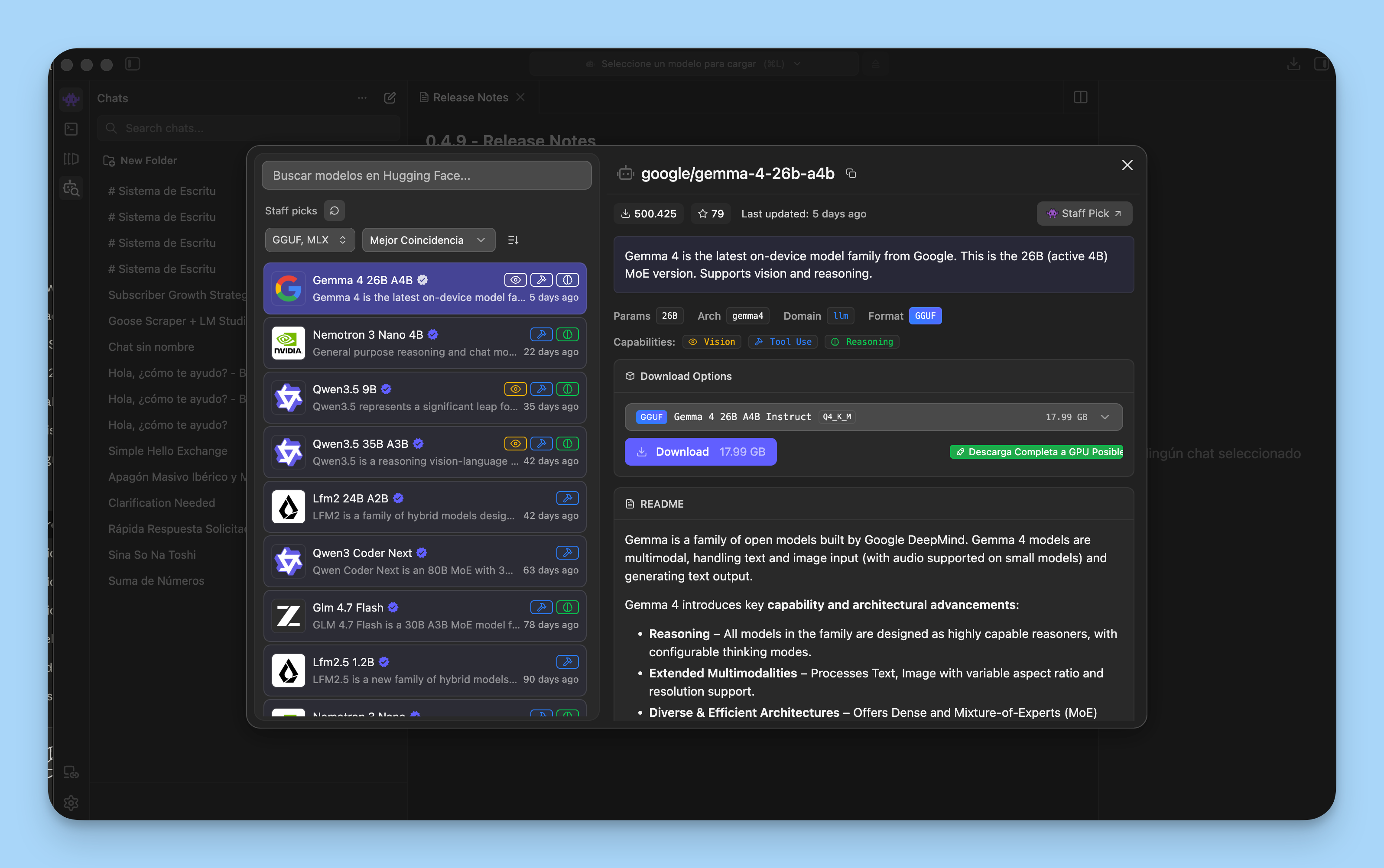
Para mi la mejor puerta de entrada a la IA Open.
Gratis para uso personal.
Interfaz visual donde buscas, descargas y ejecutas modelos con un click.
Soporta GGUF (el formato estándar para modelos cuantizados).
Chat integrado
Servidor API local compatible con OpenAI, y desde hace poco actúa como cliente MCP (puedes conectarle herramientas externas).
🔥 Lo mejor: Si solo instalas UNA cosa, que sea esta.
✅ Útil para: Tu primer contacto con IA local. Chat diario. Prototipar.
➤ Ollama 🔗 ollama.com
🖥️ Windows · macOS · Linux

El gestor de modelos por terminal. Un solo comando (ollama run gemma4) y tienes un modelo funcionando. Integración nativa con Gemma 4, Kimi K2.5, Qwen 3.5 y prácticamente todos los modelos open source relevantes desde el día 1. Si eres más de terminal que de interfaz gráfica, este es tu punto de entrada.
🔥 Lo mejor: Actualizar o cambiar modelos es un comando. Ideal para automatizaciones.
✅ Útil para: Developers. Automatizaciones. Integrar IA en tus scripts y flujos.
🥈 Nivel 2: Para sacarle más partido
➤ Open WebUI 🔗 openwebui.com

🖥️ Windows · macOS · Linux (requiere Docker o Ollama)
Interfaz web estilo ChatGPT para tus modelos locales. Se conecta a Ollama o LM Studio y te da una experiencia de chat idéntica a la de las APIs de pago — pero corriendo en tu máquina. Soporta múltiples usuarios, historial de conversaciones, RAG integrado y plugins.
🔥 Lo mejor: Si tienes un equipo, todos pueden usar los modelos locales con una interfaz bonita.
✅ Útil para: Equipos pequeños. Reemplazar ChatGPT Plus en tu empresa.
➤ AnythingLLM 🔗 anythingllm.com
🖥️ Windows · macOS · Linux
RAG para tus documentos (la capacidad de que el modelo busque y use información de tus propios archivos). Súbele PDFs, contratos, documentos internos y pregúntale lo que quieras. Interfaz visual, sin código. Se conecta a Ollama, LM Studio o cualquier API.
🔥 Lo mejor: Privacidad total con tus documentos sensibles. Nada sale de tu máquina.
✅ Útil para: Abogados, consultores, contables, cualquiera que trabaje con documentos confidenciales.
➤ Jan 🔗 jan.ai
🖥️ Windows · macOS · Linux

Alternativa open source a LM Studio, 100% código abierto (AGPLv3). Interfaz limpia, descarga de modelos integrada, extensiones. Si te importa que la herramienta en sí sea open source (no solo los modelos), Jan es tu opción.
🔥 Lo mejor: Transparencia total del código. Comunidad muy activa.
✅ Útil para: Quien quiera todo el stack genuinamente abierto.
🥉 Nivel 3: EXPERTO
➤ Unsloth 🔗 unsloth.ai
🖥️ Linux · macOS (parcial)
Windows (vía WSL) Fine-tuning eficiente. Entrena y personaliza modelos con tu propia data usando 2x menos memoria y 2x más rápido que los métodos estándar. Soporte de primera para Qwen 3.5 y Gemma 4. Sus cuantizaciones GGUF con imatrix son las mejores del ecosistema.
🔥 Lo mejor: Cuantizaciones Q4_K_XL que mantienen >99% de la calidad del modelo original.
✅ Útil para: Crear modelos especializados en tu dominio. Cuantizaciones de máxima calidad.
➤ Kimi Code 🔗 kimi.com
🖥️ Multiplataforma (CLI) CLI de coding agéntico.
La alternativa open source a Claude Code. Funciona con VSCode, Cursor y Zed. Usa imágenes y vídeos como input. Respaldado por el modelo Kimi K2.5.
🔥 Lo mejor: Visual coding — le das un screenshot de un diseño y genera el código.
✅ Útil para: Developers que quieren un copiloto de código open source.
➤ vLLM 🔗 docs.vllm.ai
🖥️ Linux (principalmente) · macOS experimental
Motor de inferencia de alta velocidad para servir modelos a escala. Continuous batching, PagedAttention, throughput brutal. Si necesitas servir modelos a múltiples usuarios simultáneos con baja latencia, esto es lo que usan los profesionales.
🔥 Lo mejor: Rendimiento de producción. Es lo que usan las empresas serias.
✅ Útil para: Desplegar IA en producción. Servir modelos a equipos grandes.
➤ SGLang 🔗 github.com/sgl-project/sglang
🖥️ Linux · macOS
Framework de inferencia y programación de LLMs. Más rápido que vLLM en muchos benchmarks. Soporte nativo para Qwen 3.5, Gemma 4 y la mayoría de modelos MoE recientes.
🔥 Lo mejor: Velocidad de inferencia. Programación estructurada de prompts.
✅ Útil para: Despliegues de producción avanzados. Pipelines complejos.
➤ Hugging Face Transformers 🔗 huggingface.co/docs/transformers
🖥️ Windows · macOS
Linux La librería estándar para cargar, ejecutar y fine-tunear modelos. Todos los modelos mencionados en este artículo tienen soporte oficial. Si sabes Python, esto es tu navaja suiza.
🔥 Lo mejor: Ecosistema gigante. Compatibilidad universal.
✅ Útil para: Desarrolladores Python. Investigación. Integración en apps propias.
El resultado: tu propia “OpenAI privada” que nunca te cobra y nunca comparte tus datos.
⚠️ Resumen sincero: Ventajas/inconvenientes
Los modelos closed-source ya no tienen ventaja técnica clara. Pero hay trade-offs reales:
✅ Lo que ganas:
Control total de tus datos - nada sale de tu infraestructura
Costes predecibles - no más sorpresas en la factura de la API
Sin rate limits - úsalo todo lo que quieras
Personalización completa - fine-tuning sin restricciones
Compliance simplificado - los datos no salen de la UE
⚠️ Lo que sacrificas:
Setup inicial que requiere ganas (30-45 min, no 30 segundos)
Mantenimiento técnico - actualizar modelos, ajustar parámetros
Hardware up-front - los modelos más avanzados requieren máquinas potentes como Mac Studio de 256 GB Ram (apple ha retirado en las últimas semans el modelo de 512GB) o DGX Spark o Nvidia 5090. Un setup profesional para ejecutar modelos potentes puede rondar los 10.000€
Sin soporte 24/7 garantizado - la comunidad es tu soporte
La ecuación real: Si usas IA es una pieza clave de tu negocio y rentabilidad, los modelos locales te ahorran dinero y te dan más control, son una opción que tienes que tener en cuenta. Si es uso ocasional, las suscripciones y APIs siguen siendo más cómodas.
Y aquí viene la perspectiva que pocos tienen: no tienes que elegir. Los profesionales inteligentes usan una estrategia híbrida.
🧩 La Estrategia Híbrida (El Verdadero Hack)
El enfoque inteligente y que es exactamente lo que el paper de NVIDIA propone:
Para tareas rápidas y rutinarias: Gemma 4 26B MoE o Qwen3.5-9B en local. Emails, planning, borradores, resúmenes. Coste: cero. Latencia: mínima.
Para desarrollo y coding: Kimi K2.5 o Qwen3.5-35B-A3B en local. Visual coding, debugging, refactoring. Sin compartir tu código con nadie.
Para razonamiento profundo o cuando el hardware no da: API de Qwen3.6 Plus (gratis) o Kimi K2 Thinking. Cuando necesitas 1M tokens de contexto o 300 pasos de tool calling.
Para el heavy lifting puntual: Claude Opus o GPT-5 vía API. Para esos 2-3 momentos al mes donde necesitas lo mejor absoluto.
Total coste mensual: entre 0€ y 50€. Versus 200-500€ de suscripciones múltiples.
Esta es la mentalidad de “sistema heterogéneo” que describe el paper. Modelos pequeños especializados para el 80% del trabajo. El modelo frontera comercial solo cuando de verdad lo necesitas.
📚 Referencias, Papers y Recursos
🔬 Papers y Publicaciones Científicas
“Small Language Models are the Future of Agentic AI” (NVIDIA / Georgia Tech, 2025) - arxiv.org/html/2506.02153v2 - El paper que argumenta por qué los modelos pequeños especializados superan a los mastodontes para flujos agénticos. Base teórica de la estrategia híbrida.
TurboQuant: Optimal Vector Quantization for KV Cache Compression (Google Research, ICLR 2026): research.google/blog/turboquant - Compresión 6x del caché KV a 3 bits sin pérdida de precisión. El avance que viabiliza modelos grandes en hardware de consumo.
Gemma 4 Model Card (Google DeepMind, abril 2026): ai.google.dev/gemma/docs/core/model_card_4 - Benchmarks detallados, arquitectura, requisitos de hardware y comparativas oficiales.
Qwen3.5: Towards Native Multimodal Agents (Alibaba Qwen Team, febrero 2026): qwen.ai/blog?id=qwen3.5 - Publicación técnica oficial con arquitectura Gated DeltaNet + MoE y todos los benchmarks.
Kimi K2: Open Agentic Intelligence (Moonshot AI) moonshotai.github.io/Kimi-K2 - Paper técnico del modelo base K2: 1T parámetros, 32B activos, benchmarks de SWE-bench y capacidades agénticas.
Gemma 4 Technical Blog (Hugging Face) huggingface.co/blog/gemma4 - Guía práctica de la comunidad para inferencia, fine-tuning y despliegue con código de ejemplo.
📊 Leaderboards y Benchmarks (Para Seguir la Evolución)
LM Arena (antes Chatbot Arena): lmarena.ai - El leaderboard de preferencia humana más citado. Rankings Elo basados en votación ciega de usuarios reales. Aquí es donde Gemma 4 31B consigue su Elo de 1452.
Hugging Face Open LLM Leaderboard: huggingface.co/spaces/open-llm-leaderboard - El leaderboard de referencia para modelos open source. Tests en IFEval, BBH, MATH, GPQA, MUSR, MMLU-PRO. Interactivo y filtrable.
Artificial Analysis: artificialanalysis.ai - Comparativas independientes de rendimiento, velocidad, precio y calidad. Su Intelligence Index es una de las métricas compuestas más citadas.
Vellum Open LLM Leaderboard: vellum.ai/open-llm-leaderboard - Benchmarks actualizados excluyendo métricas saturadas. Foco en GPQA Diamond, AIME, SWE-bench Verified y Humanity’s Last Exam.
BenchLM: benchlm.ai - Rankings compuestos con desglose por categoría (coding, math, reasoning, agentic). Actualización semanal.
Onyx Open Source LLM Leaderboard: onyx.app/open-llm-leaderboard - Tier list (S/A/B/C/D) con comparador visual directo entre modelos. Muy útil para decisiones rápidas.
LiveCodeBench: livecodebench.github.io - Benchmark de coding competitivo que se actualiza continuamente con problemas nuevos. Evita la contaminación de datos de entrenamiento.
SWE-bench Verified: swebench.com - El estándar para medir capacidad de resolver issues reales de GitHub. La métrica más relevante para coding agéntico.
🛠️ Herramientas y Modelos (Descarga Directa)
LM Studio — lmstudio.ai — Windows · macOS · Linux.
Ollama — ollama.com — Windows · macOS · Linux.
Open WebUI — openwebui.com
AnythingLLM — anythingllm.com
Jan — jan.ai — 100% open source.
Unsloth — unsloth.ai — Fine-tuning y cuantizaciones optimizadas.
Kimi Code — kimi.com — CLI de coding agéntico.
Top herramientas IA (Open Source) - Mafia IA Ranking
Modelos en Hugging Face:
Gemma 4: huggingface.co/google/gemma-4-31B-it
Qwen 3.6: huggingface.co/Qwen
✨ Mi rincón personal:
🖋 Que estoy leyendo: Lo que Nunca Cambia de Morgan Housel (lo estoy leyendo por 2ª vez) - libro imprescindible.
💪 Mi reto de este mes: Añadir a mis 30 minutos de ejercicio de fuerza diarios (sin excepción), 2 sesiones de cardio (Odio correr directamente, así que combino con cosas que me parecen más divertidas como Boxeo y partidos de squash)
🔥 Una victoria esta semana: Por fin tengo lista mi empresa, Mafia Labs S.L (y el primer proyecto será precisamente Open Source) ;)
❤️ Hoy te recomiendo: Este vídeo reflexión de Fabián C. Barrios sobre Irán. No olvidemos a las verdaderas víctimas de cualquier bando. Gente normal como tú o yo que por pura mala suerte están jodidos en medio de una maldita guerra.
🧰 En qué estoy trabajando: Memm (proyecto Open source, aquí la doc).
🚂 Desde dónde escribo: en un tren y a medio camino Santander-Madrid.
🤔 Una pregunta para reflexionar: ¿Qué es lo maravilloso de tu vida que rara vez aprecias tanto como deberías?
🎶 Una canción: la última canción que escuché antes de publicar esto: Bajo Presión - Leiva
👍 Una Newsletter recomendada:
Esto es una recomendación genuina no pagada de una newsletter que leo y que creo que a ti también te podría interesar. Dale una oportunidad.
Hoy quiero recomendaros: Hábito Nutrición, de Alfredo Andreu.
Me gusta porque no va solo de “come mejor” o “haz ejercicio”, sino de algo más difícil y más útil: conectar los hábitos de salud con una vida que realmente merezca la pena vivir. Ese enfoque cambia bastante las cosas.
Hay muchísima información sobre nutrición, suplementos, descanso o salud. El problema casi nunca es “no saber”, sino conseguir llevarlo a la práctica sin convertir tu vida en otra obligación más. Y por eso esta semana te recomiendo esta newsletter:
El Momento de la Verdad
El ecosistema open source ya no es una alternativa “para los que no pueden pagar”. Es una ventaja competitiva.
Gemma 4 demostró que Google puede hacer modelos abiertos de nivel frontier. Qwen 3.5 demostró que puedes tener eficiencia extrema con modelos tiny. Kimi K2.5 demostró que los agentes autónomos open source son viables. TurboQuant demostró que el hardware ya no es la barrera que era.
Quien domine este stack tiene una ventaja injusta sobre quien siga pagando 200€/mes por lo que ya puede tener mejor y gratis.
Los primeros en moverse como siempre serán los que consigan mejores resultados dentro de 6 meses.
Descarga LM Studio. Instala Gemma 4 o Qwen3.5-9B. Pruébalo con tus propios documentos. 30 minutos.
Si después de esos 30 minutos no entiendes por qué esto cambia las reglas, te devuelvo tu tiempo. Puedes dejarme un comentario 😅
Quizá te interese:
❤️ Gracias por leer La Mafia IA.
Si te ha gustado esta edición, házmelo saber, no te olvides de darle al ♡
o déjame un comentario con tu sistema para manejar el contexto favorito.
¿Conoces a alguien a quien le pueda ayudar esta información? → compártelo.
🗞️ Para noticias IA diarias:
La Mafia IA no te bombardea con noticias (que solo añaden ruido y caos).
Si te interesa estar más al día: En mis perfiles en redes comento las noticias más importantes en tiempo real, me puedes encontrar en:
⮕ 💼 Linkedin | 𝕏 x.com | @Thread | 📶 Telegram
Una guía muy buena, Alex. Aquí la única pega que veo es que, para tener un nivel que se acerque a lo que tenemos en ChatGPT o Claude, tenemos que tirar por equipos de al menos 32 GB de RAM. Eso es algo que, para muchos, hace que la IA local deje de ser conveniente.
Es como autoalojar un servidor de archivos o de fotos. Al final, todo depende de ti: necesitas crear copias de seguridad, mantener el servidor actualizado y, además, comprarlo o montarlo. Creo que el tema de la conveniencia sigue siendo un hándicap importante hoy en día.
De todos modos, creo que en poco tiempo esto va a cambiar.
Excelente contenido. Hace un par de meses vengo usando el siguiente stack:
Claude Code en Antigravity pasando por ollama como ejecutor.
Es decir la interfaz es Antigravity, el motor es claude y ollama es el encendido.
Así ya he construido 2 proyectos prototipos de sistemas de ventas enfocados en lead discovery y prospección. Están aún en una fase muy básica, pero arrojando los primeros resultados satisfactorios.