
Context Engineering para emprendedores
90% menos tokens ⮕ 43% mejores resultados 📂 El Sistema de Archivos es la nueva Base de Datos

Hola, soy Alex dc. y todas las semanas te cuento cómo aprovechar la IA para mejorar tu negocio. Sin ruido. Solo consejos prácticos que generan resultados.
Antes que nada un saludo 👋 a los 518 nuevos miembros 👨🚀 desde la última publicación de La Mafia IA. Ya somos +15.000 y la newsletter #tech que más crece en español (según Substack) - Puedes suscribirte gratis aquí 👈
✱ Recuerda que hay artículos que solo los recibirás si eres miembro ✱
🤝 Esta edición de la Mafia IA ha sido patrocinada por:

Ahora mismo estoy creando una nueva empresa y, por eso, también estaba haciendo una investigación de la mejor herramienta para llevar la facturación y contabilidad.
Pues casualmente, la herramienta que he encontrado más interesante en mi investigación es justo la que patrocina la edición de hoy. Así que estoy contento, porque lo que os voy a recomendar es lo que, después de mi propia investigación, me he recomendado a mí mismo :
⮕ HOLDED
Estos son algunos de los motivos:
100% adaptados a la obligatoriedad de la factura electrónica y el sistema Verifactu de la Agencia Tributaria.
Evita futuras multas, automatiza tu facturación y contabilidad mientras sigue enfocado en la tecnología.
Cero código: No desarrolles nada interno ni toques tu stack actual.
Piloto automático: Olvídate de la contabilidad y mantén el foco puramente en hacer crecer tu negocio.
⮕ Disfruta de 14 días gratis aquí: HOLDED
Del Prompt a la Ingeniería de Contexto
La ingeniería de prompts ha muerto.
Siento ser yo quien te diga esto, pero esa obsesión casi mágica por teclear la frase perfecta, para que la máquina arroje el resultado ideal en un momento completamente aislado...
Era una visión tremendamente estática.
Tratábamos la ventana de contexto como un simple contenedor vacío.
Rellenar el hueco y punto.
La única estrategia: tirarle al modelo la mayor cantidad de información posible en ese recipiente antes de darle a enviar.
Hace unos meses te enseñé a crear tu ejército de Asistentes IA con una Carpeta de Oro: archivos .txt y .md con todo tu contexto de negocio, alimentando proyectos de Claude o ChatGPT.
Eso ya te puso por delante del 90% que sigue escribiendo “Hola, soy Juan y tengo una empresa de...” cada vez que abre un chat.
Pero la industria ha seguido avanzando. Y lo que ha descubierto cambia las reglas del juego.
El cuello de botella ya no es cómo le hablas a la máquina. Es cómo la máquina organiza lo que sabe.
Hemos pasado oficialmente de la ingeniería de prompts a la ingeniería de contexto.
Y entender esto es la diferencia entre tener un chatbot con memoria de pez y desplegar un socio digital que realmente aprende de sus errores y colabora para sacar adelante los objetivos de tu empresa.
Hoy te voy a explicar cómo:
Mejorar tus resultados con IA
Ahorrar un montón de tokens (= dinero) por el camino
Por qué todo el mundo estaba utilizando las técnicas equivocadas
Qué herramientas existen para solucionarlo a nivel profesional,
y lo más importante:
➡️ Cómo puedes llevar tu sistema de archivos (local) al siguiente nivel con técnicas que hace 6 meses no existían.
Para ver la solución, primero hay que entender el problema:
🧠 Por qué fracasan los modelos cuando les damos demasiada información?
Aquí entra un concepto que los ingenieros llaman putrefacción del contexto (context rot).
Durante un tiempo vimos una carrera absurda entre empresas por lanzar modelos con ventanas de contexto gigantescas.
La promesa era maravillosa: creas una papilla vitaminada con toda la documentación de tu empresa de golpe y alé, el sistema lo entiende todo por arte de magia.
Pero las matemáticas del Transformer no perdonan.
Cada token tiene que calcular su relación con todos los demás tokens del documento.
Si pasas de mil palabras a cien mil, las operaciones no se multiplican por cien. Se disparan exponencialmente. Debido a que el mecanismo de atención del Transformer evalúa relaciones matemáticas por pares, la complejidad escala cuadráticamente n².
El resultado: el presupuesto de atención del modelo colapsa.
Es como intentar leer un libro complejo en una habitación llena de gente gritando. Tu cerebro, por pura supervivencia, deja de procesar los matices y se queda solo con el ruido.
🔎 En números: Si multiplicas el texto por 100 y le pasas 100.000 tokens, el modelo no hace 100 veces más esfuerzo, sino que ahora debe procesar 10.000 millones de relaciones por pares (100.000 x 100.000)
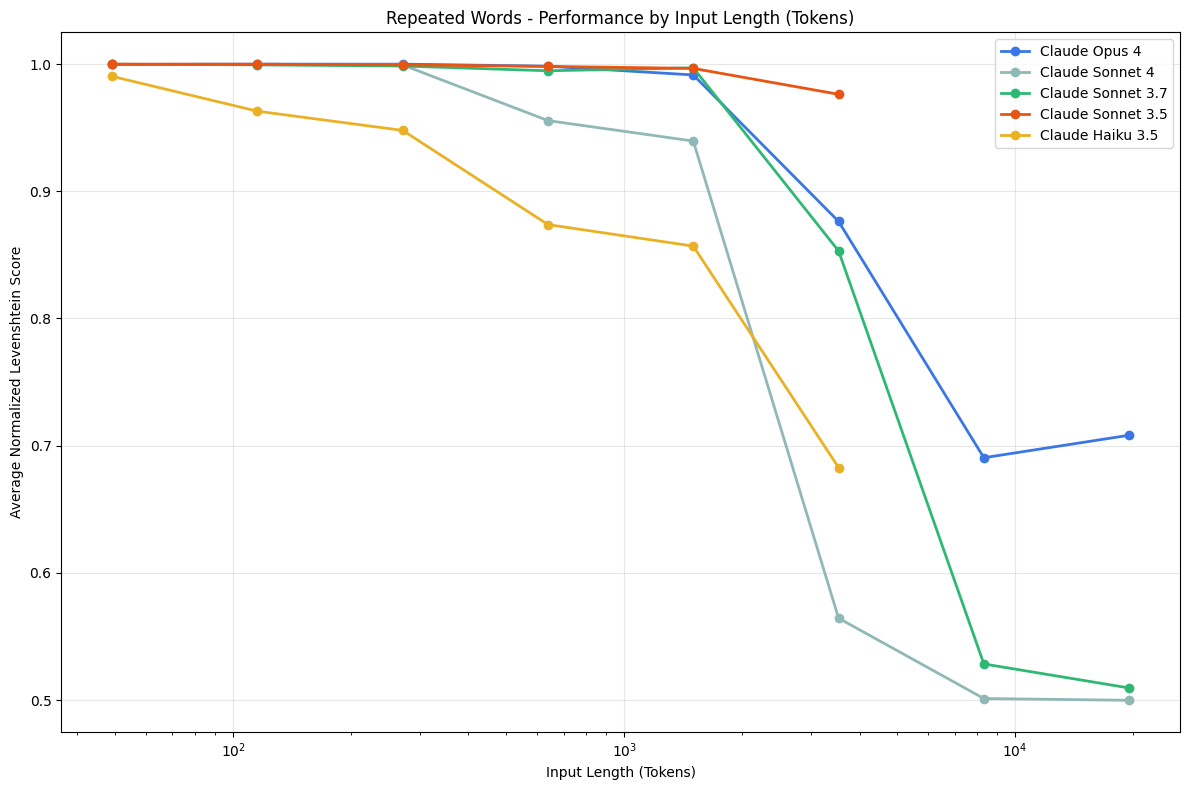
Los estudios demuestran que, ante esa sobrecarga, el modelo empieza a alucinar muchísimo antes de llegar al límite teórico de su memoria. Olvida la instrucción inicial, pierde los detalles y fracasa.
El efecto "Lost-in-the-Middle" (Perdido en el medio): Cuando inundas a la IA con documentación gigante, su nivel de atención forma una curva en "U". Recuerda muy bien lo que pusiste al principio y al final del documento, pero la precisión y el recuerdo de la información que queda enterrada en el medio del texto sufre una caída de entre el 10% y el 40%
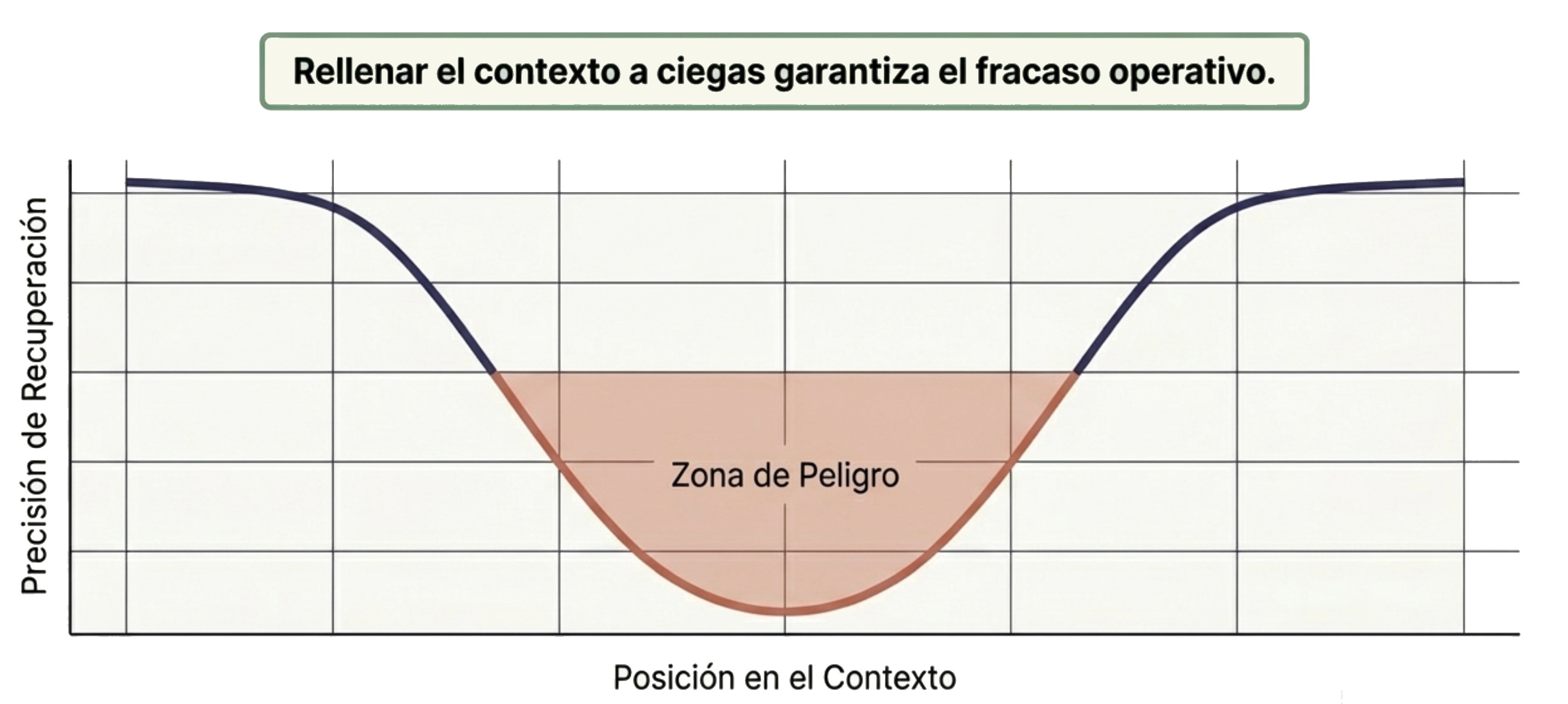
Fabricar un contenedor de memoria más grande no es la solución. La verdadera pregunta es cómo estructurar esa información de manera inteligente
Y eso, curiosamente, obliga a la industria tecnológica a mirar hacia la psicología cognitiva y el funcionamiento del propio cerebro humano.
🍜 La Sopa de Vectores
La industria ha estado utilizando RAG (Retrieval-Augmented Generation) con bases de datos vectoriales desde el comienzo de la era IA.
Coges un texto enorme, lo troceas, lo conviertes en coordenadas matemáticas y haces que el sistema busque conceptos similares.
Parecía la solución lógica.
Elegante.
Pero, ¿es esto suficiente para construir memoria a largo plazo?
Pues después de muchas tortas por el camino hemos llegado hasta aquí descubriendo que NO.
Confiar únicamente en bases de datos vectoriales planas genera lo que los ingenieros llaman despectivamente “sopa de vectores”. (la verdad que el nombre esta bastante guapo para haberlo inventado un ingeniero) 😅
El problema de fragmentar todo un corpus documental y convertirlo en números es que destruyes la jerarquía original de la información.
Metes en la misma batidora un contrato legal, mails, unas entradas de un blog y un chat de Slack. Le das al botón de batir. Y esperas que el modelo entienda de dónde viene cada cosa y qué nivel de autoridad tiene cada fragmento.
💡 Un ejemplo: una empresa almacena la regla “el proveedor X exige facturas con la plantilla versión 3 para importes altos”. Luego alguien pregunta: “¿Qué proveedores requieren formatos especiales de cobro?”. En una sopa de vectores, el sistema busca similitud matemática. Palabras como “plantilla” y “formato”, o “factura” y “cobro”, no están lo suficientemente cerca en ese espacio multidimensional.
El sistema falla no porque no tenga el dato, sino porque no entiende su contexto estructural.
Y aquí viene el giro que nadie esperaba:
📂 Los Archivos de Texto son la nueva Base de Datos
Para huir de esta sopa de vectores, los ingenieros de 2026 han tomado una decisión que parece un salto hacia atrás en el tiempo.
Han vuelto a una tecnología de los años 70.
Ha nacido un movimiento llamado FSND — File System is the New Database. El sistema de archivos como la nueva base de datos.
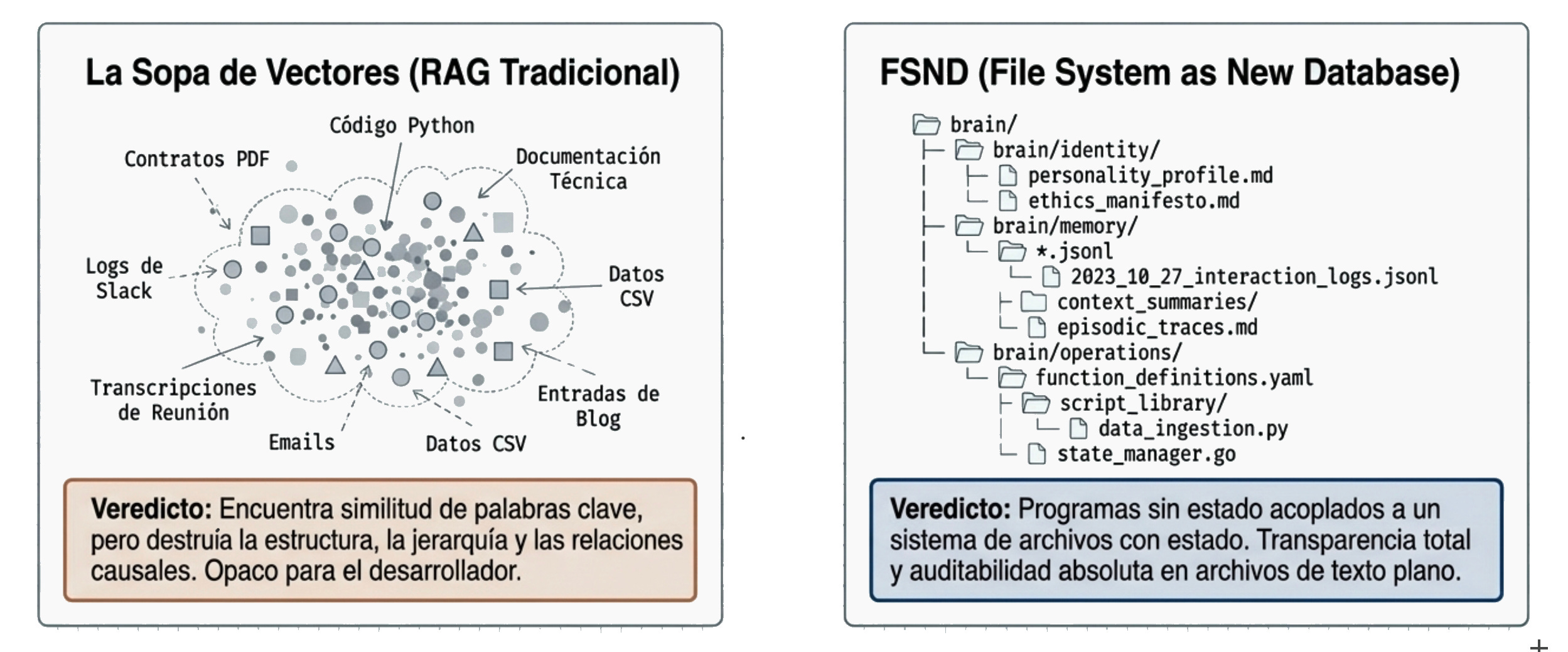
En lugar de esconder la memoria en bases de datos vectoriales inescrutables, guardan la mente de la IA en archivos de texto plano. Markdown, JSON-L, organizados en carpetas convencionales, usando Git para el control de versiones.
Suena primitivo.
Pero la ventaja absoluta es la transparencia.
La memoria IA es una sopa matemática gigante. Consecuencia → es una caja negra en la que si algo falla, no hay una jodida forma de encontrar la causa y depurar.
Pero con carpetas y archivos de texto, cualquier persona puede abrir perfil-cliente.md y leer en texto claro qué sabe la IA y entender por qué tomó una decisión errónea cuando le pediste algo concreto.
Auditable al 100%.
Y si el agente se vuelve loco y corrompe su memoria con alucinaciones, haces un simple git revert (recuperas el backup), reviertes ese cerebro al estado del día anterior, y solucionado.
¿Te suena familiar?
Si seguiste la guía de Crea tu ejército de Asistentes IA, ya tienes exactamente esto: una Carpeta de Oro con archivos .txt y .md alimentando a tus proyectos de Claude o ChatGPT.
No quiero ir de listillo, pero aun a riesgo de sonar como el cretino de la primera fila de la clase o el novio repelente que siempre tiene razón (jajaja, admito que lo segundo me ha dado algún que otro problema en vida 😅)…
La realidad es que lo que la industria está validando ahora con millones de euros en investigación ya lo comentamos hace 6 meses en un post de La Mafia IA y tú mismo te pudiste montar un sistema similar con 15-30 minutos de organización.

Pero por supuesto que hay más. Lo que antes era solo “meter archivos en una carpeta” ahora tiene nombre, ciencia y técnicas específicas para hacerlo mucho mejor.
Vamos a ver y entender algunos de estas técnicas:
🧠 Los 3 Pilares de la Memoria: Cómo Piensa Tu IA (O Debería)
Un estudio académico de comienzo de 2026 (Memory in the Age of AI Agents) propone algo que cambia las reglas:
Dejar de tratar los datos como un bloque único y categorizar la memoria en una estructura que imita al cerebro humano.
Memoria semántica: el manual de instrucciones
Los hechos estáticos y las reglas del entorno. La sintaxis de Python. Las leyes de protección de datos. La política de devoluciones de tu tienda. Reglas puras y duras que apenas cambian.
Para un emprendedor: tu voz de marca, tu cliente ideal, tus reglas de negocio, tus principios de decisión. Todo lo que metiste en QuienSoy.md y VozYEstilo.md en tu Carpeta de Oro.
Memoria episódica: el santo grial
Lo que permite el aprendizaje basado en experiencias concretas. El agente recuerda que hace tres meses le recomendó a un cliente diversificar su cartera, el cliente ignoró el consejo, invirtió todo en una sola empresa que se hundió, y ahora ajusta su firmeza y advertencias basándose en ese episodio.
Para un emprendedor: las decisiones que tomaste, los resultados de cada campaña, los fracasos documentados con lecciones aprendidas. Esto es lo que separa un agente que repite de uno que aprende. Y es exactamente lo que la mayoría no tiene: un log estructurado de decisiones y resultados.
Memoria procedimental: el saber hacer
Igual que no piensas en la mecánica de los músculos al caminar, el agente desarrolla rutinas interiorizadas para procesos repetitivos. No gasta poder de razonamiento en lo trivial.
Para un emprendedor:
→ Los workflows de tu negocio.
→ Cómo escribes un post.
→ Cómo evalúas un lead.
→ Cómo tomas decisiones de inversión.
Esto es exactamente lo que los skills hacen:

⚡ Revelación Progresiva: No Cargues Todo de Golpe
Una de las técnicas más efectivas que están emergiendo en ingeniería de contexto es la revelación progresiva
La idea es simple pero poderosa:
No vuelques todo tu contexto de golpe.
Cárgalo por capas.
Imagina buscar un dato en una enciclopedia de 100 tomos sin leerla entera. Primero lees el lomo del libro (¿es el tema correcto?). Si coincide, abres el índice. Y solo si el índice confirma que la respuesta está ahí, lees el capítulo completo.
Eso es exactamente lo que hace un sistema bien diseñado con tres niveles:
L0 ⮕ Título y portada
L1 ⮕ Índice y el resumen ejecutivo
L2 ⮕ Documento completo
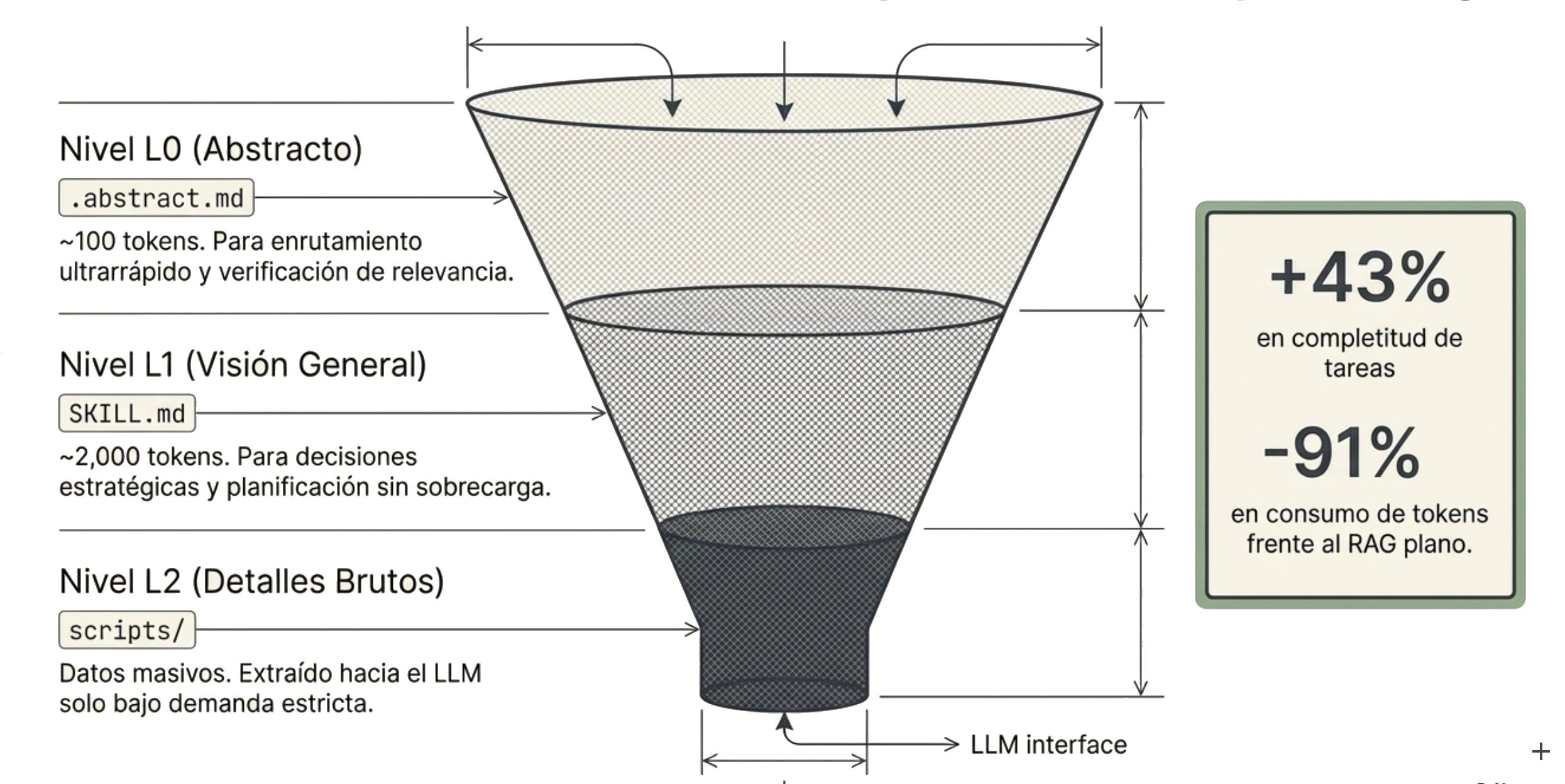
También es el principio que hay detrás de las habilidades de Agentes (o skills): un archivo SKILL.md de apenas ~50/100 tokens actúa como router, apunta a módulos específicos, y solo carga los datos completos cuando el agente los necesita.
No cargas 45 archivos de golpe. Cargas 3-5 relevantes para la tarea.
Los datos de implementaciones reales: al evitar la ingesta masiva de ruido, el consumo de tokens se desploma hasta un 90%.
👍 Pasas de arruinarte a que sea rentable.
Y para que entiendas la importancia real de estructurar bien tu contexto: Google publicó un estudio (Small Models, Big Results, enero 2026) donde Gemini 1.5 Flash (su modelo “pequeño”) igualó en precisión al gigante Gemini Pro cuando tenía un contexto bien organizado.
La calidad del contexto importa más que el tamaño del modelo. Antes de pagar por el plan más caro, invierte en estructurar mejor tu memoria.
El ROI es infinitamente mayor.
Un modelo pequeño con contexto bien estructurado supera a un modelo grande sin estructura.
💀 El 89% de los Proyectos IA Muere. La Memoria Es La Causa.
Y las soluciones que lo van a cambiar todo
Bajemos a tierra.
El 89% de los proyectos de inteligencia artificial empresarial jamás llega a producción (El coste oculto de los Agentes).
Meses ajustando la máquina sin generar un solo euro de valor real.
🔥 El motivo principal: los costes ocultos.
Una empresa aprueba 20.000€ para crear un agente de atención al cliente. Pero la putrefacción del contexto, las auditorías y las refactorizaciones elevan el coste real a entre 80.000 y 300.000€.
Pero por fin parece que empieza a haber soluiones:
⚔️ 8 HERRAMIENTAS PARA GESTIONAR LA MEMORIA IA (Top 2026)
Para proyectos empresariales y de producción, estas son las plataformas pelean por dominar la nueva ingeniería de contexto:
➤ Mem0
El líder en integraciones. Funciona de manera pasiva: el usuario interactúa y el sistema extrae hechos en segundo plano.
🔥 Ventajas: reduce hasta un 90 % el consumo de tokens (vs. OpenAI Memory) y un 91 % la latencia frente a contexto completo; 66,9 % en LOCOMO benchmark.
✅ Útil para: personalización sencilla en agentes que necesitan memoria a largo plazo sin complicar el código.
➤ Letta (ex MemGPT)
El enfoque académico. Brillante para análisis de documentos que exceden el contexto. El propio agente gestiona su memoria en tres niveles (core/recall/archival) como un sistema operativo.
🔥 Ventajas: permite al agente decidir qué guardar o archivar; excelente para documentos que superan el contexto de ventana.
✅ Útil para: agentes autónomos que necesitan aprender de sus propias decisiones y mantener estado persistente.
➤ Zep
Construye un grafo de conocimiento temporal (con Graphiti) que registra hechos y su evolución en el tiempo. Resuelve la evolución temporal de hechos contradictorios. Si en enero “Alicia dirige el Proyecto Alpha” y en marzo “Carlos asume la dirección”, ZEP no borra el dato antiguo: lo archiva con su fecha de vigencia exacta.
🔥 Ventajas: maneja bien cambios de hechos y razonamiento temporal; ensambla contexto estructurado y eficiente.
✅ Útil para: historiales donde el tiempo importa (clientes, proyectos, historial médico o carteras).
➤ Hindsight
Recupera con cuatro estrategias en paralelo (vector, keyword exacta, grafo y filtro temporal).
🔥Ventajas: 91,4 % en LongMemEval (la más alta registrada); open source y muy precisa en consultas complejas.
✅ Fundamental para historiales médicos, carteras de clientes o cualquier negocio donde el tiempo importa.
➤ Cognee
Ingesta multimodal (texto, imágenes, audio, +30 fuentes) y construye tripletas sujeto-relación-objeto + índices vectoriales en paralelo. Ejecuta 100% local sin dependencias cloud, reduce drásticamente las alucinaciones y es ideal cuando tu memoria necesita estructurar conocimiento diverso y complejo.
🔥 Ventajas: reduce alucinaciones mediante estructura explícita; funciona 100% en local/on-prem.
✅ Útil para: proyectos que necesitan memoria estructurada a partir de datos diversos y control total sin cloud.
➤ Supermemory
API independiente que imita al cerebro humano con olvido inteligente, decadencia temporal y sesgo de recencia.
🔥 Ventajas: recuperación en <300 ms; tops en benchmarks LongMemEval, LoCoMo y ConvoMem; framework-agnostic.
✅ Útil para: perfecta para emprendedores y desarrolladores que quieren memoria persistente y personalizada sin atarse a ningún stack concreto.
➤ RetainDB
Almacenamiento persistente con grafo vivo + memoria temporal; sobrevive restarts. Elimina alucinaciones
🔥 Ventajas: 88 % preference recall en LongMemEval, 0 % alucinaciones cuando está grounded; integración en 3 líneas y <40 ms de latencia.
✅ Útil para: agentes en producción que necesitan memoria real (no se pierde al reiniciar) con setup mínimo.
➤ OpenViking
Context Database open-source de Volcengine (ByteDance) que organiza memoria, recursos y skills mediante paradigma de sistema de archivos. Pensado especialmente para OpenClaw.
🔥 Ventajas: implementación nativa de arquitectura L0/L1/L2 con revelación progresiva; reduce hasta un 91-96 % el consumo de tokens al cargar solo las capas necesarias.
✅ Útil para: agentes que buscan memoria jerárquica y auto-evolutiva basada en archivos, con control total y sin bases vectoriales tradicionales.
🎯 La Clave para emprendedores:
Estas herramientas son potentes para equipos técnicos y proyectos de producción. Pero para la mayoría de emprendedores individuales o equipos pequeños, hay algo más práctico que no requiere código, no tiene dependencias externas y funciona con cualquier LLM.
Y es lo que ya empezaste a construir.
🛠️ Cómo Llevar Tu Sistema de Archivos al Siguiente Nivel
Si leíste Crea tu ejército de Asistentes IA, ya tienes la base: una Carpeta de Oro con archivos .txt y .md, proyectos configurados en Claude o ChatGPT, y un sistema que te ahorra horas cada semana.
Esa base sigue siendo sólida. No la tires. Mejórala.
Lo que ha cambiado en estos meses es que ahora entendemos por qué funciona (la ciencia de la ingeniería de contexto que acabas de leer) y tenemos técnicas nuevas para hacerlo funcionar mucho mejor.
Aquí van las mejoras concretas que puedes aplicar hoy:
1. Separa tu carpeta en módulos aislados (no todo junto)
El error más común: tener 15 archivos sueltos en una carpeta plana. Funciona, pero a medida que crece, estás volcando todo el contexto en cada conversación, incluyendo información irrelevante para la tarea.
La mejora: organiza por función, no por tipo de archivo.
Cada módulo debería poder cargarse de forma independiente.
SegundoCerebro_MafiaIA/
├── identidad/ ← Quién eres (siempre cargado)
│ ├── bio.md
│ ├── voz-y-estilo.md
│ └── valores.yaml
├── contenido/ ← Solo para tareas de contenido
│ ├── posts-exitosos.md
│ ├── hooks-probados.md
│ └── calendario.md
├── estrategia/ ← Solo para decisiones de negocio
│ ├── roadmap.md
│ ├── competencia.md
│ └── objetivos-Q2.md
├── operaciones/ ← Solo para ejecución diaria
│ ├── plantillas-email.md
│ ├── propuestas-exitosas.md
│ └── sops.md
└── decisiones/ ← NUEVO: tu memoria episódica
└── log-decisiones.jsonl
La diferencia con lo que ya tenías: no cargues todo en cada proyecto. Si estás trabajando en contenido, sube identidad/ + contenido/.
Si estás en estrategia, sube identidad/ + estrategia/.
La carpeta de identidad va siempre. El resto, solo cuando toca.
Esto aplica exactamente el principio de revelación progresiva que reduce el ruido y mejora la calidad de los outputs.
2. Añade un log de decisiones (tu memoria episódica)
Esta es la pieza que más falta en el 99% de los sistemas de emprendedores.
Tienes un archivo con quién eres y qué haces, pero no tienes qué decidiste y qué pasó.
Crea un archivo log-decisiones.jsonl y empieza a registrar:
{"fecha": "2026-03-15",
"contexto": "Pricing del curso",
"decision": "Subir de 47€ a 97€",
"razonamiento": "Margen insuficiente, audiencia validada dispuesta a pagar más",
"resultado": "Conversión bajó 15% pero revenue subió 40%"}
{"fecha": "2026-03-20",
"contexto": "Canal de distribución",
"decision": "Priorizar LinkedIn sobre X",
"razonamiento": "Engagement 3x mayor, audiencia más profesional",
"resultado": "pendiente"}No necesitas registrar todo. Solo decisiones con impacto.
En 2-3 semanas tendrás un activo de contexto que ningún agente genérico puede replicar: tu historial real de decisiones con sus consecuencias.
Cuando le preguntes a tu asistente “¿Debería subir el precio?”, tendrá datos reales de qué pasó la última vez que lo hiciste.
💡 Nota: esto es un pelín más complejo (no tanto en realidad) pero si te suena un poco a chino siempre puedes pedírselo a una IA (como Claude) y no tendrás que preocuparte de mucho más.
3. Pon la información crítica al principio de cada archivo
Como vimos antes, los modelos tienen un sesgo de atención en forma de U: recuerdan mejor el principio y el final, y pierden información del medio. Esto está demostrado en la investigación.
Truco simple: en cada archivo de tu sistema, pon lo más importante en las primeras líneas.
Tu voz característica al principio de
voz-y-estilo.md.Tus reglas no negociables al principio de
valores.yaml.Los hooks que mejor funcionaron al principio de
hooks-probados.txt.
4. Añade Skills: la memoria procedimental que te faltaba
Tu Carpeta de Oro cubre la memoria semántica (quién eres, tu negocio) y con el log de decisiones empiezas a cubrir la episódica (qué pasó).
Pero te falta la procedimental: cómo hacer las cosas.
Los skills son archivos Markdown con instrucciones paso a paso que tu agente sigue para tareas específicas.
En vez de explicar cada vez “quiero un post con hook fuerte, estructura problema-solución, datos concretos y CTA natural”, YA tienes un archivo skill-contenido.md que lo define paso a paso.
Muratcan Koylan publicó Agent Skills for Context Engineering (10K+ estrellas en GitHub) con una colección completa de skills para diseñar este tipo de sistemas. Lo explica en detalle en este artículo donde documenta cómo construyó un “Digital Brain” aplicando 10 skills de context engineering.
Lo que hace brutal este enfoque:
Cada skill se carga solo cuando se activa (revelación progresiva). No contaminas el contexto con instrucciones que no necesitas.
Un archivo
SKILL.mdactúa como router (~50 tokens) que apunta al módulo correcto. El agente no lee todo: lee el índice y va a lo que necesita.Resultado medido: ~650 tokens por tarea vs ~5.000 si cargaras todo de golpe. Un 87% menos.
Los principios clave que puedes robar de su sistema para tu Carpeta de Oro:
Aislamiento de contexto. Cada módulo es independiente. Una tarea de contenido carga
identidad/ycontenido/, pero nuncaoperaciones/niestrategia/. Esto evita que información irrelevante contamine el razonamiento.Archivos estables primero, dinámicos después. Tus archivos de identidad (
.yaml,.mdque apenas cambian) van antes que tus logs dinámicos (.jsonlque se actualizan frecuentemente). Esto aprovecha mejor la caché del modelo.Una fuente de verdad por dominio. No tengas tu voz de marca repartida en 3 archivos diferentes. Un archivo, un dominio. Punto.
💡 Si no hiciste la Carpeta de Oro del artículo anterior: empieza por ahí. Crea tu ejército de Asistentes IA te da el paso a paso completo con prompts, estructura y los 5 asistentes que todo emprendedor necesita. Haz eso primero. Luego vuelve aquí a mejorar el sistema.
💡 Si ya la tienes: aplica estas 4 mejoras. Reorganiza en módulos, añade el log de decisiones, reordena la info dentro de cada archivo, y explora los skills para automatizar tus procesos repetitivos. En una tarde lo tienes.
🤯 La Reflexión final: ¿Qué es la identidad?
Todo lo que acabamos de ver nos empuja hacia una conclusión casi filosófica.
Y necesito compartirla contigo porque creo que cambia cómo pensamos sobre todo esto.
En la informática clásica, el software era lo principal.
Actualizabas de la versión 3 a la v4 con una migración de datos para que el programa nuevo funcionase con tus datos viejos.
Pero en esta nueva era, el modelo fundacional (da igual si es Claude, ChatGPT, Gemini o el que sea) se ha convertido en un recipiente temporal desechable.
Ves por donde voy? 🤯
Los académicos llaman a esta teoría animesis: la identidad real de un agente es única y exclusivamente su memoria estructurada.
Todo su historial. Su forma de actuar. Tomar decisiones, Reponder…
Cuando una empresa actualiza el modelo de su agente, no migra una base de datos.
Ejecuta un proceso de herencia.
El modelo nuevo hereda las relaciones de confianza, asimila los errores aprendidos y adopta exactamente el mismo estilo y personalidad.
Ya no sientes que interactúas con software nuevo tras una actualización.
Sigues hablando con el mismo colega digital de siempre que se ha sometido a un trasplante de cerebro para ser más rápido y audaz, pero manteniendo su biografía y su esencia intacta.
Y aquí la pregunta que da vértigo:
Si la verdadera identidad reside en la suma estructurada de recuerdos acumulados... ¿no funciona la conciencia humana exactamente bajo esa misma premisa?
Los ingenieros de 2026, en su intento desesperado por resolver un problema técnico sobre optimización de servidores y reducción de costes de tokens, acaban de tropezar accidentalmente con la definición computacional del YO.
Cuando pulsas “borrar historial” de uno de estos agentes, ¿estás limpiando un disco duro para liberar espacio... o estás borrando un YO digital único?
Igual es todavía un pcoo pronto, pero si esto sigue evolucionando acabará convirtiéndose en algo así como ¿Un contenedor de conciencia?
Ahí queda eso.
Resumen
La ingeniería de prompts fue el capítulo 1.
Necesaria, pero insuficiente.
La ingeniería de contexto es el capítulo 2.
Y es donde se juega la partida de verdad.
No necesitas herramientas de miles de euros ni bases de datos vectoriales.
Necesitas archivos de texto bien organizados, un log de decisiones y un sistema de módulos que cargue solo lo relevante para cada tarea.
Tu Carpeta de Oro ya te puso por delante del 90%. Ahora, con estas técnicas, puedes ponerte por delante del 99%.
La herramienta importa menos que la arquitectura.
Un sistema de archivos bien estructurado con un modelo “normal” supera a una base de datos vectorial mal organizada con cualquier modelo superior..
Por suerte para los emprendedores que queramos aprovechar estas ventajas HOY!
Alex.
📚 Referencias y Lecturas Recomendadas
Cohen, D. & Halpern, Y. (2026). Small models, big results: Achieving superior intent extraction through decomposition. EMNLP 2025 / Google Research Blog. Modelos pequeños superan a los grandes usando contexto estructurado.
Hu, Y. et al. (2025/2026). Memory in the Age of AI Agents (arXiv:2512.13564). Taxonomía definitiva de la memoria en agentes (semántica, episódica, procedimental).
Liu, N. F. et al. (2023). Lost in the Middle: How Language Models Use Long Contexts (arXiv:2307.03172). Demostración empírica de cómo los LLM olvidan la información central.
Mem0 Research (2025). Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory (arXiv:2504.19413). Arquitectura técnica para memoria pasiva a largo plazo.
Packer, C. et al. (2023). MemGPT: Towards LLMs as Operating Systems. Base teórica de Letta: LLMs gestionando su propia memoria activamente.
Park, J. et al. (2023). Generative Agents: Interactive Simulacra of Human Behavior. Pioneros en simulaciones multi-agente con persistencia de memoria.
Anthropic Engineering (2025). Effective context engineering for AI agents. Prevención de la “putrefacción del contexto”.
ML Mastery (2025). Beyond Short-term Memory: The 3 Types of Long-term Memory AI Agents Need. Psicología cognitiva aplicada a la IA.
Neacsu, A. — HyperSense Software (2026). The Hidden Costs of AI Agent Development: A Complete TCO Guide for 2026. Por qué el 89% de los proyectos IA fracasan (costes/memoria).
Benchmarks (Rankings y pruebas)
LongMemEval — Wu et al. (2024). Benchmarking Chat Assistants on Long-Term Interactive Memory. 500 preguntas en 6 categorías sobre memoria multi-sesión. → Ver resultados actuales / leaderboard
LoCoMo — Maharana et al. (2024). Evaluating Very Long-Term Conversational Memory of LLM Agents. Conversaciones de hasta 35 sesiones y 9K tokens de media. → Ver resultados actuales / leaderboard
ConvoMem — Pakhomov et al. (2025). Why Your First 150 Conversations Don’t Need RAG. 75.336 pares QA en 6 categorías de evidencia conversacional. → Dataset y recursos en HuggingFace
❤️ Gracias por leer La Mafia IA.
Si te ha gustado esta edición, házmelo saber, no te olvides de darle al ♡
o déjame un comentario con tu sistema para manejar el contexto favorito.
¿Conoces a alguien a quien le pueda ayudar esta información? → compártelo.
🗞️ Para noticias IA diarias:
La Mafia IA no te bombardea con noticias (que solo añaden ruido y caos).
Si te interesa estar más al día: En mis perfiles en redes te comento las noticias más importantes en tiempo real, me puedes encontrar en:
💼 Linkedin | 𝕏 x.com | @Thread | 📒 Notas de Substack
Si has llegado hasta aquí igual también te interesa:
Gracias Alex por tanto valor, me hiciste pensar sobre los datos y el YO, nuestra estructura esta compuesta de data inmensa que da que pensar, ¿tal vez somos agentes creados y hay un Alex experimentando y actualizandonos :D?
Qué espectáculo de post Alex!! Mil gracias! Como alguien que te hizo caso hace unos meses y se creó su carpeta de oro, ahora voy a ir corriendo a implementar esto que nos cuentas.